-
实时调整 Neovim 的颜色主题
需求背景
如果日常使用 Neovim 较多的话,选择一个喜欢的颜色主题还是非常不错的。Github 上面有很多 Neovim 主题插件。 但是在使用过程中会遇到这样情况,比如:“我觉得这个主题某个字段高亮颜色看着不喜欢,想做一个微调”。 一般遇到这种情况大多数人会 Fork 仓库进行修改,或者在配置文件设定主题后方进行覆盖。
早期功能实现
以上的这个功能需求,其实很久以前就有了,早期我的解决方法非常简单, 有两种:
在主题设定后方直接修改
早期的配置文件比较简单,我都是在主题设定后方直接修改的,比如:
colorschem one hi VertSplit guibg=#282828 guifg=#181A1F这种修改方式也存在弊端,就是在启动 Neovim 后,如果执行
:colorscheme命令切换主题,那配置文件中的微调将不再生效。使用
ColorScheme事件调用覆写函数。autocmd ColorScheme * call s:fix_colorscheme() function! s:fix_colorscheme() " 使用 g:colors_name 判断主题名称 " 再此使用 highlight 命令修改高亮组 endfunction这就解决了前面提到的切换主题后不再生效的问题。但是调整的过着无法在 Vim 里面完成,可能需要借助外部的调色板,调整好后把 hex 值写进配置文件。
使用 cpicker.nvim 实时调色
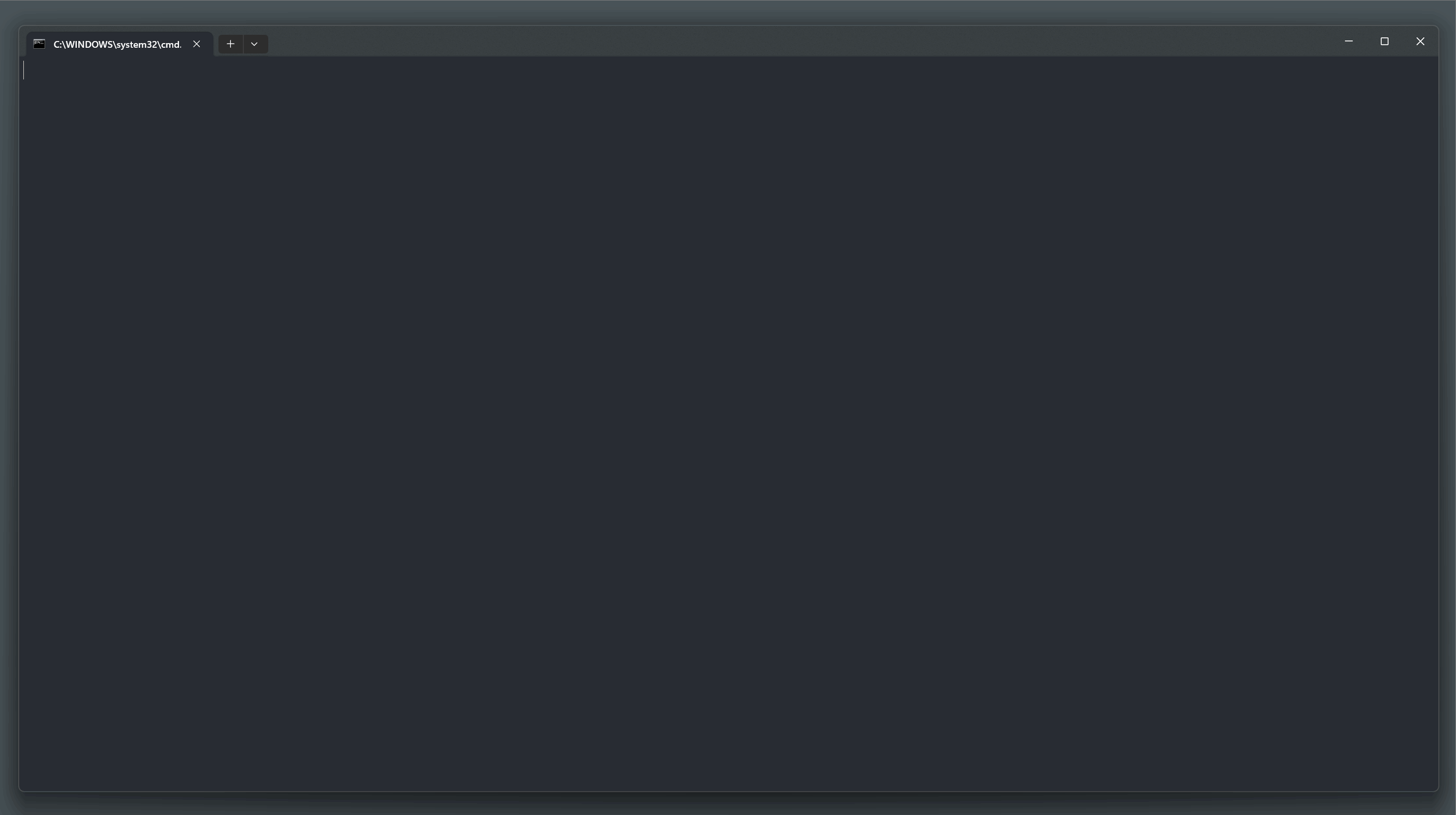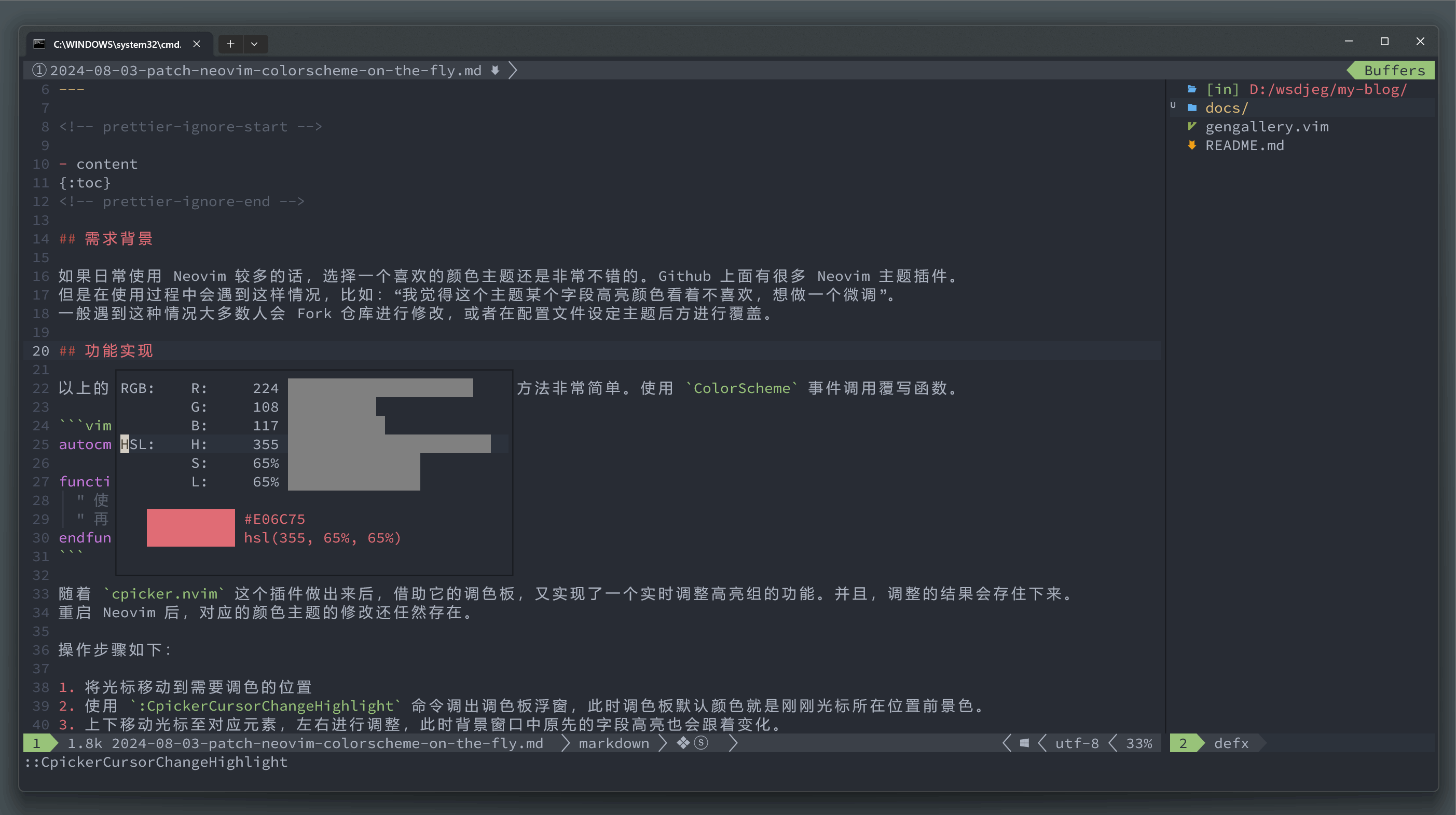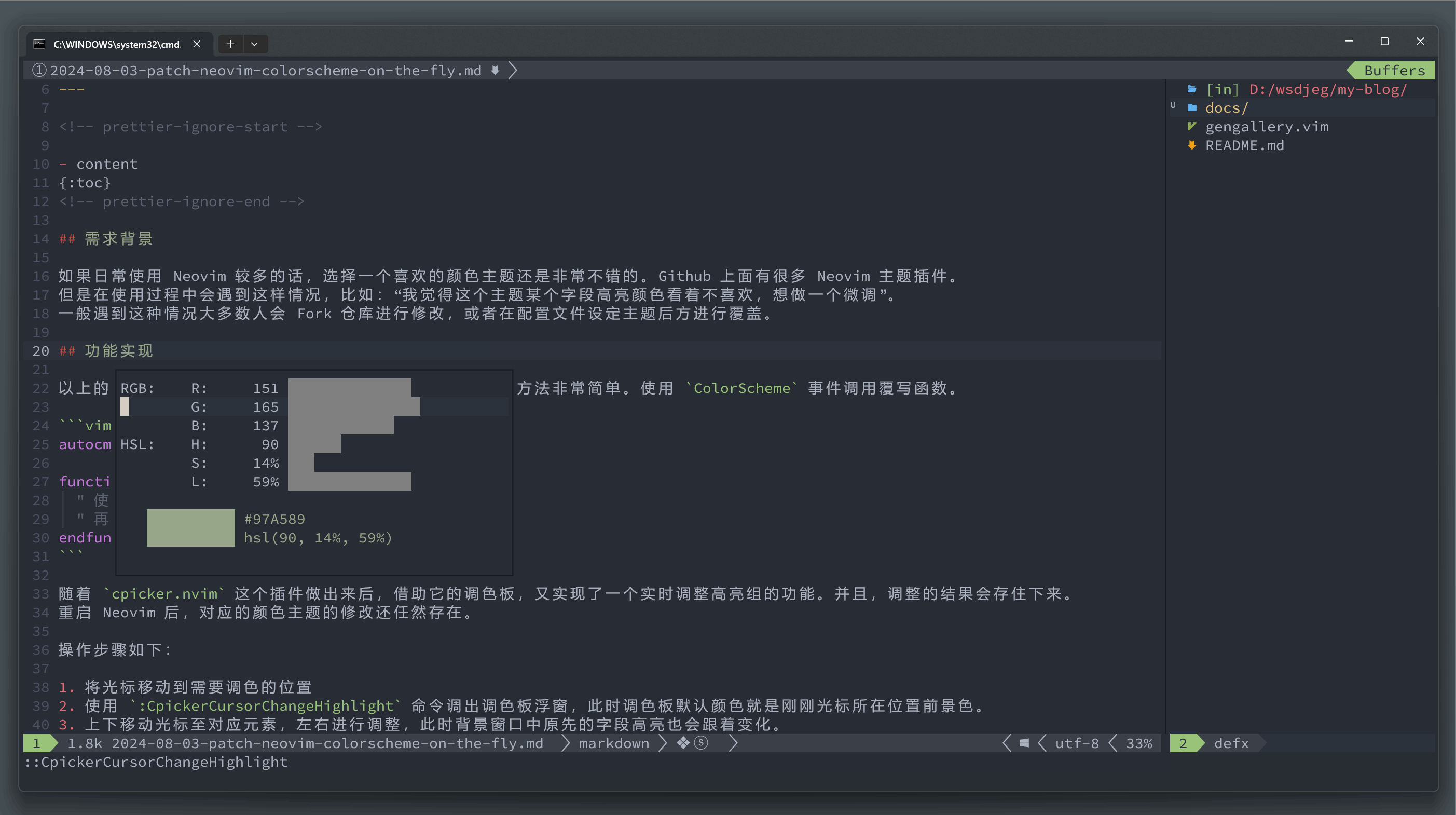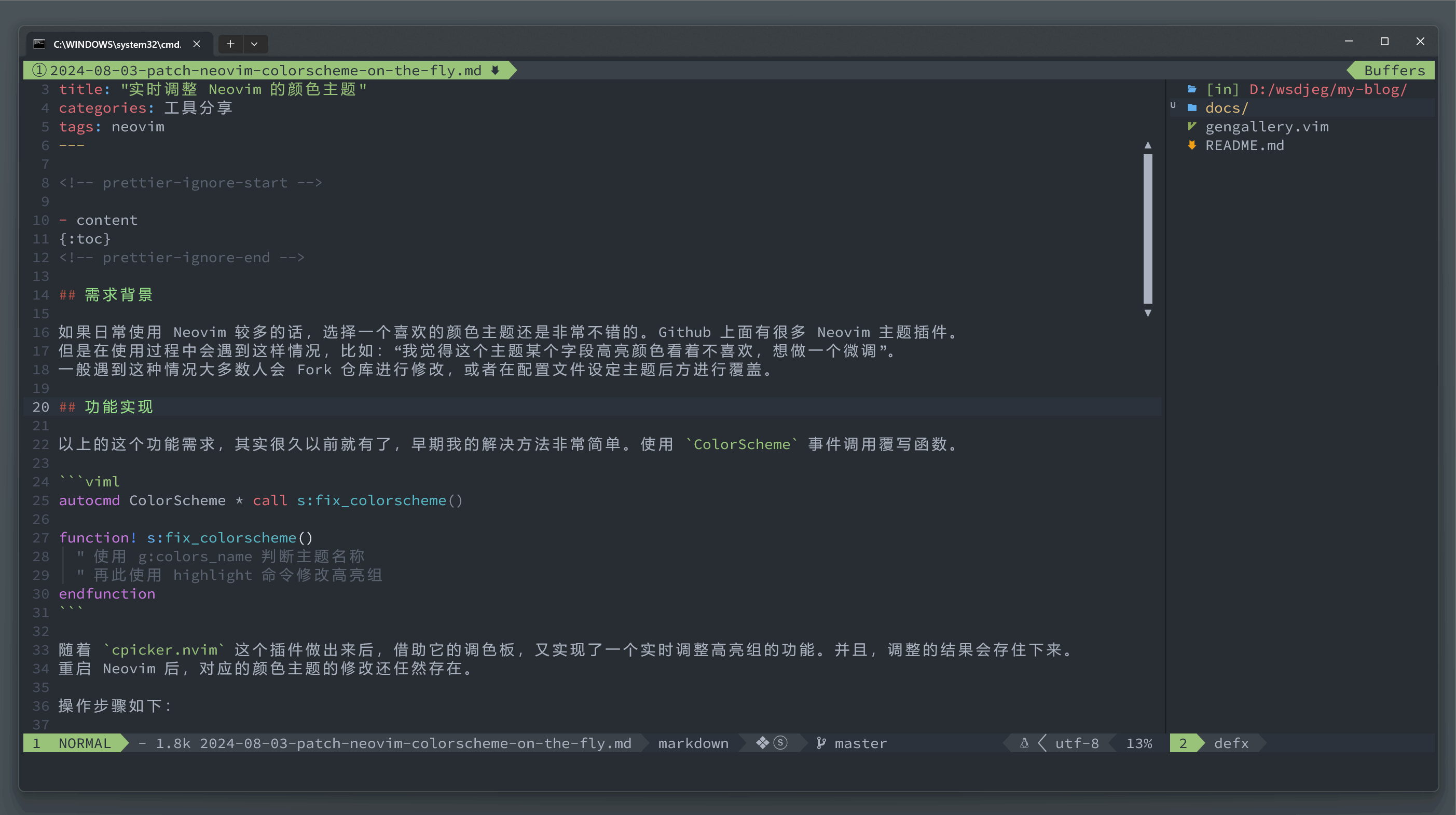
前面介绍过我的 cpicker.nvim 插件,随着这个插件做出来后,借助它的调色板,又实现了一个实时调整高亮组的功能。并且,调整的结果会存住下来。 重启 Neovim 后,对应的颜色主题的修改还任然存在。
操作步骤如下:
- 将光标移动到需要调色的位置
- 使用
:CpickerCursorChangeHighlight命令调出调色板浮窗,此时调色板默认颜色就是刚刚光标所在位置前景色。 - 上下移动光标至对应元素,左右进行调整,此时背景窗口中原先的字段高亮也会跟着变化。
- 调整完成后,使用
q按键关闭调色板浮窗。
到此时已经调整完成,如果重启 Neovim 后,对当前这个主题调整任然会生效。
我录制了一个修改颜色及重启 Neovim 并设定颜色主题的动画:
对于调整过的颜色主题,如果需要清除掉调整,只需要执行
:CpickerClearColorPatch命令。
-
悬浮滚动条插件 scrollbar.vim
插件简介
今天给大家分享一下我的 “新” 插件: scrollbar.vim。
这是一个支持 Neovim 和 Vim 的悬浮滚动条插件, 使用的是 Neovim 的 floating windows 或者 Vim 的 popup windows 特性。 相关内容可以阅读: Neovim 的
:h api-floatwin或者 Vim 的:h popup-window。之所以前面的新字加上引号,是因为实际上这个插件早在三年多前就已经在 SpaceVim 中使用了,是参考 Xuyuanp/scrollbar.nvim 逻辑重新使用 Vim Script 实现的。
在 SpaceVim 仓库下执行:
:Git log autoload/SpaceVim/plugins/scrollbar.vim* f1617ae12 - Add scrollbar support (#3826) (Wang Shidong 3 years, 10 months ago)随着后来对该插件进行不断的完善,以及针对新版本的 Neovim 重新实现的一个新的 Lua 版本, 目前插件已经基本稳定,可以独立使用,其代码执行的基本逻辑如下:
if has('nvim-0.9.0') lua require('spacevim.plugin.scrollbar').show() else call SpaceVim#plugins#scrollbar#show() endif问题反馈
目前,插件的维护及开发还是在 SpaceVim 的
bundle/scrollbar.vim目录中,使用 Github Action 同步到单独的仓库以便于直接使用。如果在使用过程中遇到问题,或者有新的想法建议,欢迎在 issue tracker 留言反馈。
安装及使用
如果你是 SpaceVim 用户,只需要在 ui 模块内启用 scrollbar 即可:
[[layers]] name = 'ui' enable_scrollbar = true对于非 SpaceVim 用户,也可以使用你喜欢的插件管理器进行安装,比如:
- vim-plug
Plug 'wsdjeg/scrollbar.vim'- lazy.vim
-- lazy.nvim { "wsdjeg/scrollbar.vim", event = "VeryLazy", }
-
关于 Neovim 插件开发的指南
今天,在 Neovim 中文电报群有人分享了一个仓库 nvim-best-practices@24e835c, 是关于 Neovim 插件开发的一些“指南”,或者可以说是“建议”,当然我也回复了我的想法,抱歉,语言有些过激。
花花里胡巧的限制,我只看了开头就看不下去了,举例,命令要分成子命令, 这个除了浪费一层判断,没啥用。本来只定义一个FooInstall命令, 实际上在底层c就已经判断出来对应的函数。结果按照他这样, 需要在viml或者lua这边判断下到底这个命令是做什么的 跟谷歌的viml style guide相比差远了。另外手机上打开毫无阅读体验可谈。起初本来不是特别在意,只在群里回复一下就算了,因为习惯每个人都有,只要 “can work” 就没必要纠结对与错了,因为毕竟也不会影响到自己的习惯。 但是随着浏览发现,居然要把这一内容合并到 Neovim 主仓库。 那我觉得就对我自己包括后来的 Neovim 用户都会有很大的影响。 因此我觉得有必要针对这个指南,写一些东西了。
逐行看一下,因为 Pull Request 的分支的一直在变动,而且是 force push,
:(,因此原文在文章中有直接文字体现。*lua-plugin.txt* Nvim:h lua-plugin很容易让人误解,也很难将内容与这个关键词联想在一起。 如果是针对于命令定义、按键映射定义的建议,那么就不局限于 Lua 了。 而且,这个不是某个 plugin 的文档,而是插件开发的建议,:h plugin-dev或者:h plugin-dev-guide感觉更加合适一些。NVIM REFERENCE MANUAL Guide to developing Lua plugins for Nvim Type |gO| to see the table of contents. ============================================================================== Introduction *lua-plugin* This is a guide for getting started with Nvim plugin development. It is not intended as a set of rules, but as a collection of recommendations for good practices. For a guide to using Lua in Nvim, please refer to |lua-guide|. ============================================================================== Type safety *lua-plugin-type-safety* Lua, as a dynamically typed language, is great for configuration. It provides virtually immediate feedback. But for larger projects, this can be a double-edged sword, leaving your plugin susceptible to unexpected bugs at the wrong time. You can leverage LuaCATS https://luals.github.io/wiki/annotations/ annotations, along with lua-language-server https://luals.github.io/ to catch potential bugs in your CI before your plugin's users do. ------------------------------------------------------------------------------ Tools *lua-plugin-type-safety-tools* - lua-typecheck-action https://github.com/marketplace/actions/lua-typecheck-action - luacheck https://github.com/lunarmodules/luacheck for additional linting ============================================================================== User commands *lua-plugin-user-commands* Many users rely on command completion to discover available user commands. If a plugin pollutes the command namespace with lots of commands, this can quickly become overwhelming. Example: - `FooAction1 {arg}` - `FooAction2 {arg}` - `FooAction3` - `BarAction1` - `BarAction2` Instead of doing this, consider gathering subcommands under scoped commands and implementing completions for each subcommand. Example: - `Foo action1 {arg}` - `Foo action2 {arg}` - `Foo action3` - `Bar action1` - `Bar action2`对于这点,我其实是持否定态度的。命令在定义时,其执行内容与字符串名字已经进行了绑定。 在调用命令时,底层 c 逻辑就已经判断出要去执行哪一个函数。 如果使用子命令,无疑要增加一个命令功能的分析,显得有些浪费。 如果一个插件只提拱了有限的几个命令, 比如:
FooInstall、FooUninstall,很明显就可以看出这两个命令的功能,根本没必要使用子命令。当然,什么样情况下建议使用子命令呢?当多个命令的字面内容非常接近且难以区分时时,比如:
FooInstall1FooInstall2
这种情况下,建议用子命令,比如
FooInstall 1,FooInstall 2或者,Foo install 1,Foo install 2------------------------------------------------------------------------------ Subcommand completions example *lua-plugin-user-commands-completions-example* In this example, we want to provide: - Subcommand completions if the user has typed `:Foo ...` - Argument completions if they have typed `:Foo {subcommand}` First, define a type for each subcommand, which has: - An implementation: A function which is called when executing the subcommand. - An optional command completion callback, which takes the lead of the subcommand's arguments. >lua ---@class FooSubcommand ---@field impl fun(args:string[], opts: table) ---@field complete? fun(subcmd_arg_lead: string): string[] < Next, we define a table mapping subcommands to their implementations and completions: >lua ---@type table<string, FooSubcommand> local subcommand_tbl = { action1 = { impl = function(args, opts) -- Implementation (args is a list of strings) end, -- This subcommand has no completions }, action2 = { impl = function(args, opts) -- Implementation end, complete = function(subcmd_arg_lead) -- Simplified example local install_args = { "first", "second", "third", } return vim.iter(install_args) :filter(function(install_arg) -- If the user has typed `:Foo action2 fi`, -- this will match 'first' return install_arg:find(subcmd_arg_lead) ~= nil end) :totable() end, -- ... }, } < Then, create a Lua function to implement the main command: >lua ---@param opts table :h lua-guide-commands-create local function foo_cmd(opts) local fargs = opts.fargs local subcommand_key = fargs[1] -- Get the subcommand's arguments, if any local args = #fargs > 1 and vim.list_slice(fargs, 2, #fargs) or {} local subcommand = subcommand_tbl[subcommand_key] if not subcommand then vim.notify("Foo: Unknown command: " .. subcommand_key, vim.log.levels.ERROR) return end -- Invoke the subcommand subcommand.impl(args, opts) end < See also |lua-guide-commands-create|. Finally, we register our command, along with the completions: >lua -- NOTE: the options will vary, based on your use case. vim.api.nvim_create_user_command("Foo", foo_cmd, { nargs = "+", desc = "My awesome command with subcommand completions", complete = function(arg_lead, cmdline, _) -- Get the subcommand. local subcmd_key, subcmd_arg_lead = cmdline:match("^Foo[!]*%s(%S+)%s(.*)$") if subcmd_key and subcmd_arg_lead and subcommand_tbl[subcmd_key] and subcommand_tbl[subcmd_key].complete then -- The subcommand has completions. Return them. return subcommand_tbl[subcmd_key].complete(subcmd_arg_lead) end -- Check if cmdline is a subcommand if cmdline:match("^Foo[!]*%s+%w*$") then -- Filter subcommands that match local subcommand_keys = vim.tbl_keys(subcommand_tbl) return vim.iter(subcommand_keys) :filter(function(key) return key:find(arg_lead) ~= nil end) :totable() end end, bang = true, -- If you want to support ! modifiers }) < ============================================================================== Keymaps *lua-plugin-keymaps* Avoid creating keymaps automatically, unless they are not controversial. Doing so can easily lead to conflicts with user |mapping|s. NOTE: An example for uncontroversial keymaps are buffer-local |mapping|s for specific file types or floating windows. A common approach to allow keymap configuration is to define a declarative DSL https://en.wikipedia.org/wiki/Domain-specific_language via a `setup` function. However, doing so means that - You will have to implement and document it yourself. - Users will likely face inconsistencies if another plugin has a slightly different DSL. - |init.lua| scripts that call such a `setup` function may throw an error if the plugin is not installed or disabled. As an alternative, you can provide |<Plug>| mappings to allow users to define their own keymaps with |vim.keymap.set()|. - This requires one line of code in user configs. - Even if your plugin is not installed or disabled, creating the keymap won't throw an error. Another option is to simply expose a Lua function or |user-commands|. However, some benefits of |<Plug>| mappings over this are that you can - Enforce options like `expr = true`. - Expose functionality only for specific |map-modes|. - Expose different behavior for different |map-modes| with a single |<Plug>| mapping, without adding impurity or complexity to the underlying Lua implementation. NOTE: If you have a function that takes a large options table, creating lots of |<Plug>| mappings to expose all of its uses could become overwhelming. It may still be beneficial to create some for the most common ones. ------------------------------------------------------------------------------ Example *lua-plugin-plug-mapping-example* In your plugin: >lua vim.keymap.set("n", "<Plug>(SayHello)", function() print("Hello from normal mode") end, { noremap = true }) vim.keymap.set("v", "<Plug>(SayHello)", function() print("Hello from visual mode") end, { noremap = true }) < In the user's config: >lua vim.keymap.set({"n", "v"}, "<leader>h", "<Plug>(SayHello)") < ============================================================================== Initialization *lua-plugin-initialization* Newcomers to Lua plugin development will often put all initialization logic in a single `setup` function, which takes a table of options. If you do this, users will be forced to call this function in order to use your plugin, even if they are happy with the default configuration. Strictly separated configuration and smart initialization allow your plugin to work out of the box. NOTE: A well designed plugin has minimal impact on startup time. See also |lua-plugin-lazy-loading|. Common approaches to a strictly separated configuration are: - A Lua function, e.g. `setup(opts)` or `configure(opts)`, which only overrides the default configuration and does not contain any initialization logic. - A Vimscript compatible table (e.g. in the |vim.g| or |vim.b| namespace) that your plugin reads from and validates at initialization time. See also |lua-vim-variables|. Typically, automatic initialization logic is done in a |plugin| or |ftplugin| script. See also |'runtimepath'|. ============================================================================== Lazy loading *lua-plugin-lazy-loading* When it comes to initializing your plugin, assume your users may not be using a plugin manager that takes care of lazy loading for you. Making sure your plugin does not unnecessarily impact startup time is your responsibility. A plugin's functionality may evolve over time, potentially leading to breakage if users have to hack into the loading mechanisms. Furthermore, a plugin that implements its own lazy initialization properly will likely have less overhead than the mechanisms used by a plugin manager or user to load that plugin lazily. ------------------------------------------------------------------------------ Defer `require` calls *lua-plugin-lazy-loading-defer-require* |plugin| scripts should not eagerly `require` Lua modules. For example, instead of: >lua local foo = require("foo") vim.api.nvim_create_user_command("MyCommand", function() foo.do_something() end, { -- ... }) < which will eagerly load the `foo` module and any other modules it imports eagerly, you can lazy load it by moving the `require` into the command's implementation. >lua vim.api.nvim_create_user_command("MyCommand", function() local foo = require("foo") foo.do_something() end, { -- ... }) < NOTE: For a Vimscript alternative to `require`, see |autoload|. NOTE: In case you are worried about eagerly creating user commands, autocommands or keymaps at startup: Plugin managers that provide abstractions for lazy-loading plugins on such events will need to create these themselves. ------------------------------------------------------------------------------ Filetype-specific functionality *lua-plugin-lazy-loading-filetype* Consider making use of |filetype| for any functionality that is specific to a filetype, by putting the initialization logic in a `ftplugin/{filetype}.lua` script. ------------------------------------------------------------------------------ Example *lua-plugin-lazy-loading-filetype-example* A plugin tailored to Rust development might have initialization in `ftplugin/rust.lua`: >lua if not vim.g.loaded_my_rust_plugin then -- Initialize end -- NOTE: Using `vim.g.loaded_` prevents the plugin from initializing twice -- and allows users to prevent plugins from loading -- (in both Lua and Vimscript). vim.g.loaded_my_rust_plugin = true local bufnr = vim.api.nvim_get_current_buf() -- do something specific to this buffer, -- e.g. add a |<Plug>| mapping or create a command vim.keymap.set("n", "<Plug>(MyPluginBufferAction)", function() print("Hello") end, { noremap = true, buffer = bufnr, }) < ============================================================================== Configuration *lua-plugin-configuration* Once you have merged the default configuration with the user's config, you should validate configs. Validations could include: - Correct types, see |vim.validate()| - Unknown fields in the user config (e.g. due to typos). This can be tricky to implement, and may be better suited for a |health| check, to reduce overhead. ============================================================================== Troubleshooting *lua-plugin-troubleshooting* ------------------------------------------------------------------------------ Health checks *lua-plugin-troubleshooting-health* Provide health checks in `lua/{plugin}/health.lua`. Some things to validate: - User configuration - Proper initialization - Presence of Lua dependencies (e.g. other plugins) - Presence of external dependencies See also |vim.health| and |health-dev|. ------------------------------------------------------------------------------ Minimal config template *lua-plugin-troubleshooting-minimal-config* It can be useful to provide a template for a minimal configuration, along with a guide on how to use it to reproduce issues. ============================================================================== Versioning and releases *lua-plugin-versioning-releases* Consider - Using SemVer https://semver.org/ tags and releases to properly communicate bug fixes, new features, and breaking changes. - Automating versioning and releases in CI. - Publishing to luarocks https://luarocks.org, especially if your plugin has dependencies or components that need to be built; or if it could be a dependency for another plugin. ------------------------------------------------------------------------------ Further reading *lua-plugin-versioning-releases-further-reading* - Luarocks <3 Nvim https://github.com/nvim-neorocks/sample-luarocks-plugin有点强推 Luarocks。
------------------------------------------------------------------------------ Tools *lua-plugin-versioning-releases-tools* - luarocks-tag-release https://github.com/marketplace/actions/luarocks-tag-release - release-please-action https://github.com/marketplace/actions/release-please-action - semantic-release https://github.com/semantic-release/semantic-release这些内容写在 wiki 或者一些单独的文章里足够了,合并到 Neovim 文档里面显得有些过了。并不是每个人都用 git 或者 github。
============================================================================== Documentation *lua-plugin-documentation* Provide vimdoc (see |help-writing|), so that users can read your plugin's documentation in Nvim, by entering `:h {plugin}` in |command-mode|. ------------------------------------------------------------------------------ Tools *lua-plugin-documentation-tools*以上两个 tag 完全可以合并,每个内容太少了点,最后这一大段,看了满屏 tag。
- panvimdoc https://github.com/kdheepak/panvimdoc
-
Neovim 调色板插件 cpicker.nvim
因为偶尔需要修改 Neovim 的高亮,涉及到颜色调整,以往使用的是外部工具,来回切换非常麻烦。 也找了一些 Neovim/Vim 的插件,但是使用的感觉确实不尽如人意。因此,自己实现了一个简便版本的调色板插件
cpicker.nvim, 该插件存储于 Github 。启用插件
可以使用任意插件管理器进行安装,比如我的 nvim-plug:
require('plug').add({ { 'wsdjeg/cpicker.nvim', depends = { { 'wsdjeg/logger.nvim' }, { 'wsdjeg/notify.nvim' }, }, }, })操作界面
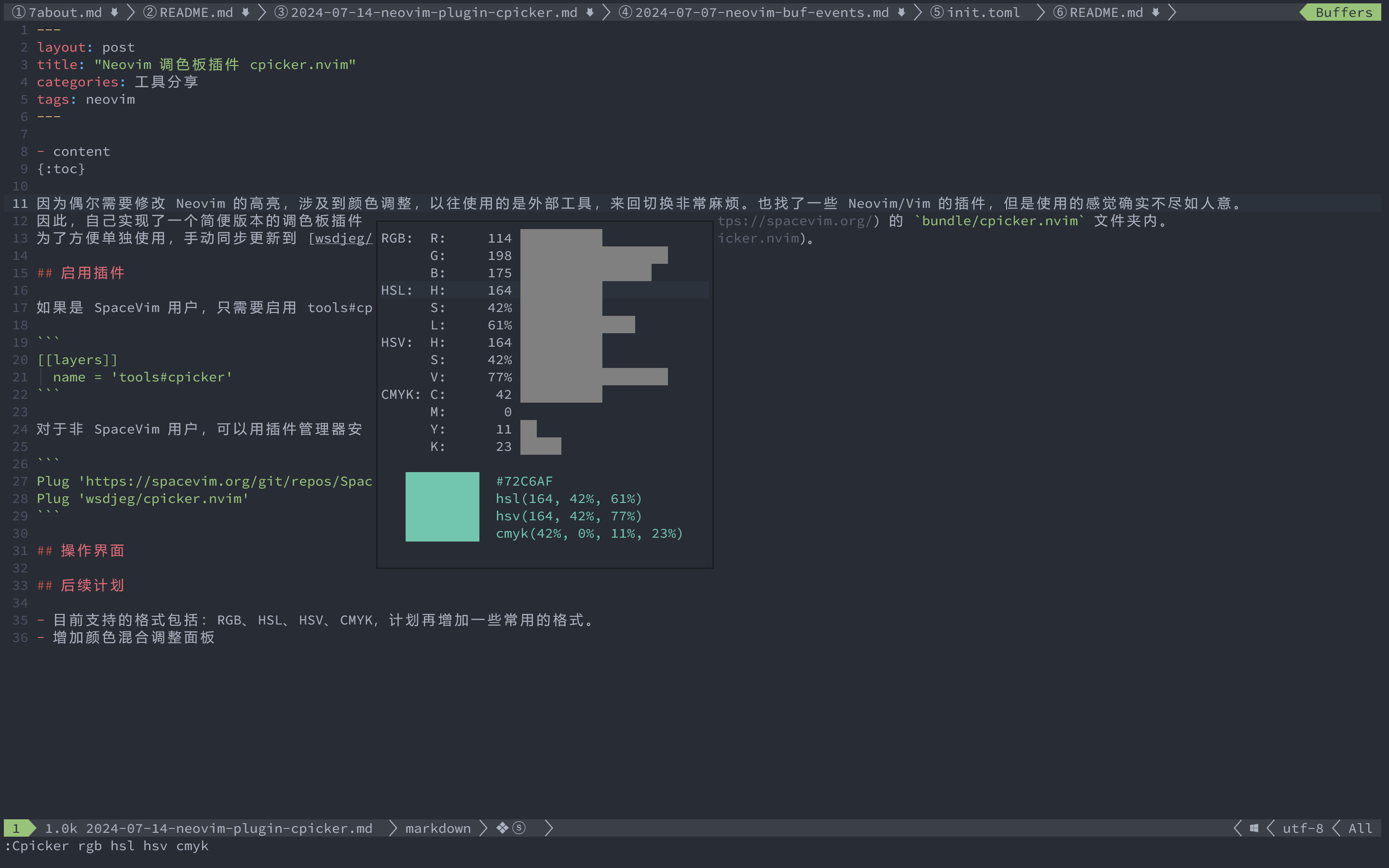
操作快捷键:
按键 功能描述 h/<Left>减小光标下的值 l/<Right>增加光标下的值 <Enter>复制光标下的颜色值 后续计划
- 目前支持的格式包括:RGB、HSL、HSV、CMYK,计划再增加一些常用的格式。
- 增加颜色混合调整面板
-
Neovim 缓冲区(buffer)相关事件
起因
最近在使用 SpaceVim 的标签栏(tabline)时发现,对于新增的空内容的缓冲区(buffer),标签栏上方并不会列出。 检查源码发现标签栏跟踪缓冲区新增的代码只监听了:
BufNewFile跟BufReadPost事件。vim.api.nvim_create_autocmd({ 'BufNewFile', 'BufReadPost' }, { callback = vim.schedule_wrap(function(event) if vim.api.nvim_buf_is_valid(event.buf) and index(right_hide_bufs, event.buf) == -1 and index(visiable_bufs, event.buf) == -1 and index(left_hide_bufs, event.buf) == -1 then table.insert(right_hide_bufs, event.buf) end end), group = tabline_augroup, })测试发现
:enew命令及:new命令并不会触发这两个事件。修改源码增加监听BufNew事件。虽然问题是修复了,但是我觉得有必要整理下缓冲区相关事件的触发时机。
获取可用事件列表
可以使用命令
:echo getcompletion('Buf', 'event')快速查看当前 Neovim 版本支持的缓冲区事件列表。事件的触发时机
BufAdd
- 新增一个缓冲区至缓冲区列表
- 将一个 unlisted 缓冲区添加进 listed 缓冲区列表
- 修改 listed 缓冲区列表中某个缓冲区的名称
BufNew
- 新增一个缓冲区
- 修改缓冲区的名称
BufNewFile
- 当开始编辑一个不存在的文件时
测试示例
通过一些实例来测试事件触发的时机,测试代码如下:
需要忽略掉
*Cmd事件,避免文件读写失败。local log = require("spacevim.logger").derive("logevent") local group = vim.api.nvim_create_augroup("logevent", { clear = true }) vim.api.nvim_create_autocmd( vim.tbl_filter(function(e) return not vim.endswith(e, "Cmd") end, vim.fn.getcompletion("Buf", "event")), { callback = vim.schedule_wrap(function(event) log.debug(event.event .. event.buf) end), group = group, } )- 执行命令:
:new
[ logevent ] [13:20:39:562] [ Debug ] BufNew5 [ logevent ] [13:20:39:562] [ Debug ] BufAdd5 [ logevent ] [13:20:39:562] [ Debug ] BufAdd5 [ logevent ] [13:20:39:562] [ Debug ] BufLeave4 [ logevent ] [13:20:39:562] [ Debug ] BufEnter5 [ logevent ] [13:20:39:562] [ Debug ] BufWinEnter5- 执行命令:
:enew
[ logevent ] [13:22:42:452] [ Debug ] BufNew6 [ logevent ] [13:22:42:452] [ Debug ] BufAdd6 [ logevent ] [13:22:42:452] [ Debug ] BufAdd6 [ logevent ] [13:22:42:452] [ Debug ] BufLeave4 [ logevent ] [13:22:42:452] [ Debug ] BufWinLeave4 [ logevent ] [13:22:42:452] [ Debug ] BufHidden4 [ logevent ] [13:22:42:452] [ Debug ] BufEnter6 [ logevent ] [13:22:42:452] [ Debug ] BufWinEnter6- 执行命令:
:echo bufadd('')
[ logevent ] [13:47:57:482] [ Debug ] BufNew6echo nvim_create_buf(v:false, v:true)
[ logevent ] [14:25:06:555] [ Debug ] BufNew5echo nvim_create_buf(v:true, v:true)
[ logevent ] [14:26:32:389] [ Debug ] BufNew11 [ logevent ] [14:26:32:389] [ Debug ] BufAdd11 [ logevent ] [14:26:32:389] [ Debug ] BufAdd11当打开一个文件后,执行
:set nobuflisted, 在执行:set buflisted[ logevent ] [14:38:15:888] [ Debug ] BufDelete4 [ logevent ] [14:38:19:857] [ Debug ] BufAdd4 [ logevent ] [14:38:19:857] [ Debug ] BufAdd4打开一个存在的文件:
:e README.md[ logevent ] [14:44:15:717] [ Debug ] BufNew8 [ logevent ] [14:44:15:717] [ Debug ] BufAdd8 [ logevent ] [14:44:15:717] [ Debug ] BufAdd8 [ logevent ] [14:44:15:717] [ Debug ] BufLeave4 [ logevent ] [14:44:15:717] [ Debug ] BufWinLeave4 [ logevent ] [14:44:15:717] [ Debug ] BufHidden4 [ logevent ] [14:44:15:717] [ Debug ] BufReadPre8 [ logevent ] [14:44:15:717] [ Debug ] BufReadPost8 [ logevent ] [14:44:15:717] [ Debug ] BufReadPost8 [ logevent ] [14:44:15:717] [ Debug ] BufEnter8 [ logevent ] [14:44:15:717] [ Debug ] BufWinEnter8打开一个不存在的新文件:
:e newfile.txt[ logevent ] [14:45:56:519] [ Debug ] BufNew10 [ logevent ] [14:45:56:519] [ Debug ] BufAdd10 [ logevent ] [14:45:56:519] [ Debug ] BufAdd10 [ logevent ] [14:45:56:519] [ Debug ] BufLeave4 [ logevent ] [14:45:56:519] [ Debug ] BufWinLeave4 [ logevent ] [14:45:56:519] [ Debug ] BufHidden4 [ logevent ] [14:45:56:519] [ Debug ] BufNewFile10 [ logevent ] [14:45:56:519] [ Debug ] BufEnter10 [ logevent ] [14:45:56:519] [ Debug ] BufWinEnter10上述功能,做成了一个独立的 Neovim 插件:wsdjeg/logevent.nvim
可以使用 nvim-plug 直接安装:
require('plug').add({ 'wsdjeg/logevent.nvim', })
-
(Neo)Vim 括号补全插件比较
起因
输入模式下,成对符号的自动补全一直是比较常用的功能。使用了很多年 delimitMate , 基本功能正常,但是偶尔会出现卡屏现象,等一段时间或者按下
ctrl-c可以结束卡屏,但是会输入很多个<Plug>delimitMate(。 但是这一现象并无法百分百重现。想着这么多年过去了,会不会有新的更好用的插件,于是搜了下,目前已知的括号补全插件有:
- delimitMate
- neopairs.vim:需要
exists('#CompleteDone') == 1 - nvim-autopairs:需要 Neovim 0.7.0+
- mini.pairs
- auto-pairs
- autoclose.nvim
- ultimate-autopair.nvim
实现逻辑及功能比较
auto-pairs
仓库中 Vim 脚本只有
plugin/auto-pairs.vim(673 行)。 监听BufEnter事件,映射g:AutoPairs所设定的成对符号。neopairs.vim
通过监听
CompleteDone事件,判断补全 item 的结尾是否匹配设定的成对符号。nvim-autopairs
是使用 Lua 实现的 Neovim 插件。在 nvim-autopairs.setup 函数里使用以下三组事件监听来实现补全。
local group = api.nvim_create_augroup('autopairs_buf', { clear = true }) api.nvim_create_autocmd({ 'BufEnter', 'BufWinEnter' }, { --- M.on_attach }) api.nvim_create_autocmd('BufDelete', { --- }) api.nvim_create_autocmd('FileType', { --- })在
M.on_attach函数里,主要有一个expr映射及一个InsertCharPre事件监听:local enable_insert_auto = false -- 初始化是否插入的 flag local expr_map = function(key) api.nvim_buf_set_keymap(bufnr, 'i', key, '', { expr = true --- 设定 expr 映射 }) end for _, rule in pairs(rules) do -- 根据每个规则映射快捷键,并计算是 enable_insert_auto 值 end if enable_insert_auto then api.nvim_create_autocmd('InsertCharPre', { --- 如果 enable_insert_auto 为 true, 则监听 InsertCharPre 事件 }) end维护状态
repo Github stars Issues pull requests last commit auto-pairs 4.1k 138 Open / 155 Closed 27 Open / 53 Closed Feb 27, 2019 delimitMate 2k 47 Open / 219 Closed 5 Open / 36 Closed Dec 14, 2020 nvim-autopairs 3k 12 Open / 287 Closed 1 Open / 157 Closed May 20 2024 neopairs.vim 31 0 Open / 4 Closed 0 Open / 0 Closed Mar 16, 2016 mini.pairs 仓库有2个:mini.nvim、mini.pairs。 因为 mini.nvim 仓库实际上是由几十个独立插件组合而成,其 Issues 跟 pull requests 列表应对到 mini.pairs 上到底有多少,无法评估。
auto-pairs 有一个较活跃的 fork 版本LunarWatcher/auto-pairs,目前维护状态正常: