-
Ruby 函数
Ruby 方法与其他编程语言中的函数类似。Ruby 方法用于捆绑一个或多个重复的语句到一个单元中。
方法名应以小写字母开头。如果您以大写字母作为方法名的开头,Ruby 可能会把它当作常量,从而导致不正确地解析调用。
方法应在调用之前定义,否则 Ruby 会产生未定义的方法调用异常。
语法
def method_name [( [arg [= default]]...[, * arg [, &expr ]])] expr.. end所以,您可以定义一个简单的方法,如下所示:
def method_name expr.. end您可以定义一个接受参数的方法,如下所示:
def method_name (var1, var2) expr.. end您可以为参数设置默认值,如果方法调用时未传递必需的参数则使用默认值:
def method_name (var1=value1, var2=value2) expr.. end当您要调用方法时,只需要使用方法名即可,如下所示:
method_name但是,当您调用带参数的方法时,您在写方法名时还要带上参数,例如:
method_name 25, 30使用带参数方法最大的缺点是调用方法时需要记住参数个数。例如, 如果您向一个接受三个参数的方法只传递了两个参数,Ruby 会显示错误。
#!/usr/bin/ruby # -*- coding: UTF-8 -*- def test(a1="Ruby", a2="Perl") puts "编程语言为 #{a1}" puts "编程语言为 #{a2}" end test "C", "C++" test从方法返回值
Ruby 中的每个方法默认都会返回一个值。这个返回的值是最后一个语句的值。例如:
def test i = 100 j = 10 k = 2 end tvar = test puts tvar在调用这个方法时,将返回最后一个声明的变量 k。
return 语句
Ruby 中的 return 语句用于从 Ruby 方法中返回一个或多个值。 语法
return [expr[',' expr...]]如果给出超过两个的表达式,包含这些值的数组将是返回值。如果未给出表达式,nil 将是返回值。
实例
return 或 return 12 或 return 1,2,3看看下面的实例:
#!/usr/bin/ruby def test i = 100 j = 200 k = 300 return i, j, k end var = test puts var可变数量的参数
假设您声明了一个带有两个参数的方法,当您调用该方法时,您同时还需要传递两个参数。
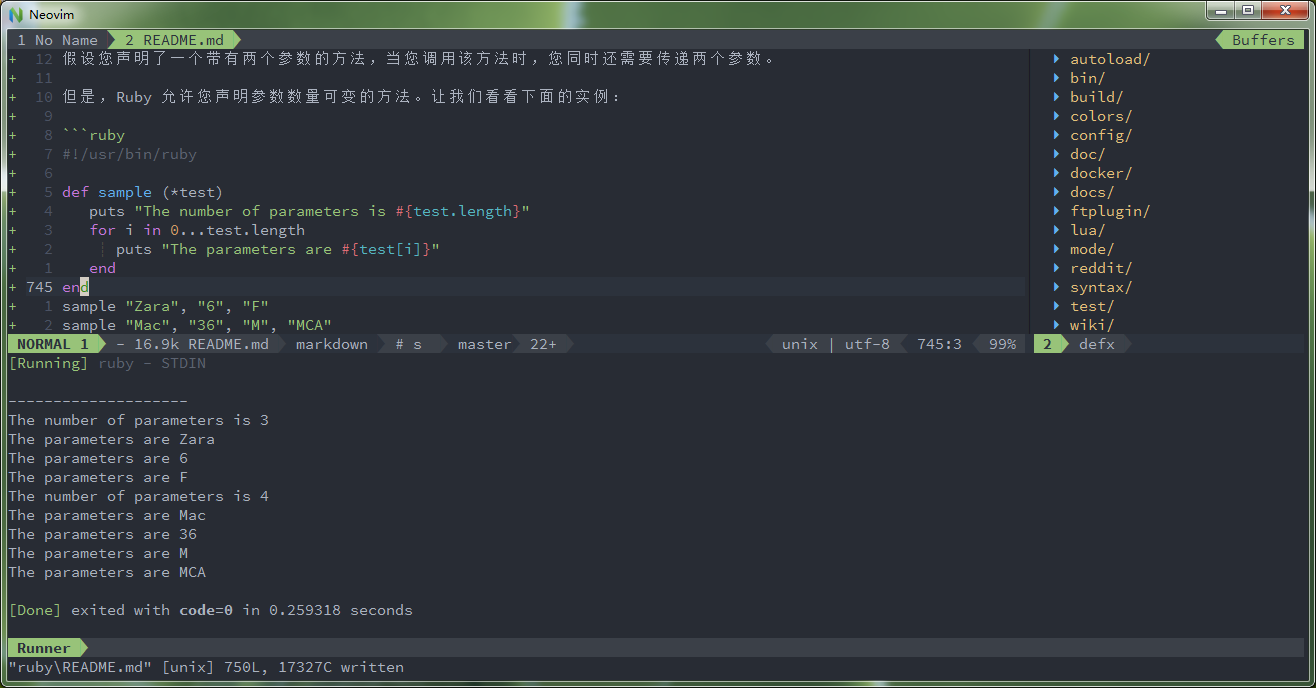
但是,Ruby 允许您声明参数数量可变的方法。让我们看看下面的实例:
#!/usr/bin/ruby def sample (*test) puts "The number of parameters is #{test.length}" for i in 0...test.length puts "The parameters are #{test[i]}" end end sample "Zara", "6", "F" sample "Mac", "36", "M", "MCA"在这段代码中,您已经声明了一个方法 sample,接受一个参数 test。但是,这个参数是一个变量参数。这意味着参数可以带有不同数量的变量。所以上面的代码将产生下面的结果:
类方法
当方法定义在类定义外部时,方法默认标记为 private。另一方面,定义在类定义中的方法默认标记为 public。方法默认的可见性和 private 标记可通过模块(Module)的 public 或 private 改变。
当你想要访问类的方法时,您首先需要实例化类。然后,使用对象,您可以访问类的任何成员。
Ruby 提供了一种不用实例化类即可访问方法的方式。让我们看看如何声明并访问类方法:
class Accounts def reading_charge end def Accounts.return_date puts "2019" end end # 我们已经知道方法 return_date 是如何声明的。 # 它是通过在类名后跟着一个点号,点号后跟着方法名来声明的。 # 您可以直接访问类方法,如下所示: Accounts.return_date如需访问该方法,您不需要创建类 Accounts 的对象。
alias 语句
这个语句用于为方法或全局变量起别名。别名不能在方法主体内定义。即使方法被重写,方法的别名也保持方法的当前定义。
为编号的全局变量($1, $2,…)起别名是被禁止的。重写内置的全局变量可能会导致严重的问题。
语法
alias 方法名 方法名 alias 全局变量 全局变量实例
alias foo bar alias $MATCH $&在这里,我们已经为 bar 定义了别名为 foo,为 $& 定义了别名为 $MATCH。
undef 语句
这个语句用于取消方法定义。undef 不能出现在方法主体内。
通过使用 undef 和 alias,类的接口可以从父类独立修改,但请注意,在自身内部方法调用时,它可能会破坏程序。
语法
undef 方法名实例
下面的实例取消名为 bar 的方法定义:
undef bar
-
Ruby 循环
Ruby 中的循环用于执行相同的代码块若干次。
while 语句
语法
while conditional [do] code end或者
<pre> while conditional [:] code end当 conditional 为真时,执行 code。
语法中 do 或 : 可以省略不写。但若要在一行内写出 while 式,则必须以 do 或 : 隔开条件式或程式区块。
实例
#!/usr/bin/ruby # -*- coding: UTF-8 -*- $i = 0 $num = 5 while $i < $num do puts("在循环语句中 i = #$i" ) $i +=1 endwhile 修饰符
语法
code while condition或者
begin code end while conditional当 conditional 为真时,执行 code。
如果 while 修饰符跟在一个没有 rescue 或 ensure 子句的 begin 语句后面,code 会在 conditional 判断之前执行一次。 实例
#!/usr/bin/ruby # -*- coding: UTF-8 -*- $i = 0 $num = 5 begin puts("在循环语句中 i = #$i" ) $i +=1 end while $i < $numuntil 语句
until conditional [do] code end当 conditional 为假时,执行 code。
语法中 do 可以省略不写。但若要在一行内写出 until 式,则必须以 do 隔开条件式或程式区块。
实例
#!/usr/bin/ruby # -*- coding: UTF-8 -*- $i = 0 $num = 5 until $i > $num do puts("在循环语句中 i = #$i" ) $i +=1; enduntil 修饰符
语法
code until conditional或者
begin code end until conditional当 conditional 为假时,执行 code。
如果 until 修饰符跟在一个没有 rescue 或 ensure 子句的 begin 语句后面,code 会在 conditional 判断之前执行一次。
实例
#!/usr/bin/ruby # -*- coding: UTF-8 -*- $i = 0 $num = 5 begin puts("在循环语句中 i = #$i" ) $i +=1; end until $i > $numfor 语句
语法
for variable [, variable ...] in expression [do] code end针对 expression 中的每个元素分别执行一次 code。
实例
#!/usr/bin/ruby # -*- coding: UTF-8 -*- for i in 0..5 puts "局部变量的值为 #{i}" end在这里,我们已经定义了范围 0..5。语句 for i in 0..5 允许 i 的值从 0 到 5(包含 5)。
for…in 循环几乎是完全等价于:
(expression).each do |variable[, variable...]| code end但是,for 循环不会为局部变量创建一个新的作用域。
语法中 do 可以省略不写。但若要在一行内写出 for 式,则必须以 do 隔开条件式或程式区块。
实例
#!/usr/bin/ruby # -*- coding: UTF-8 -*- (0..5).each do |i| puts "局部变量的值为 #{i}" endbreak 语句
语法
break终止最内部的循环。如果在块内调用,则终止相关块的方法(方法返回 nil)。
实例
#!/usr/bin/ruby # -*- coding: UTF-8 -*- for i in 0..5 if i > 2 then break end puts "局部变量的值为 #{i}" endnext 语句
语法
next跳到最内部循环的下一个迭代。如果在块内调用,则终止块的执行(yield 或调用返回 nil)。
实例
#!/usr/bin/ruby # -*- coding: UTF-8 -*- for i in 0..5 if i < 2 then next end puts "局部变量的值为 #{i}" endredo 语句
语法
redo重新开始最内部循环的该次迭代,不检查循环条件。如果在块内调用,则重新开始 yield 或 call。
实例
#!/usr/bin/ruby # -*- coding: UTF-8 -*- for i in 0..5 if i < 2 then puts "局部变量的值为 #{i}" redo end end这将产生以下结果,并会进入一个无限循环:
retry 语句
语法
retry如果 retry 出现在 begin 表达式的 rescue 子句中,则从 begin 主体的开头重新开始。
begin do_something # 抛出的异常 rescue # 处理错误 retry # 重新从 begin 开始 end如果 retry 出现在迭代内、块内或者 for 表达式的主体内,则重新开始迭代调用。迭代的参数会重新评估。
for i in 1..5 retry if some_condition # 重新从 i == 1 开始 end实例
#!/usr/bin/ruby # -*- coding: UTF-8 -*- for i in 1..5 retry if i > 2 puts "局部变量的值为 #{i}" end这将产生以下结果,并会进入一个无限循环:
-
ruby 流程控制
Ruby 提供了其他现代语言中很常见的条件结构。在这里,我们将解释所有的条件语句和 Ruby 中可用的修饰符。
if…else 语句
if conditional [then] code... [elsif conditional [then] code...]... [else code...] endif 表达式用于条件执行。值 false 和 nil 为假,其他值都为真。请注意,Ruby 使用 elsif,不是使用 else if 和 elif。 如果 conditional 为真,则执行 code。如果 conditional 不为真,则执行 else 子句中指定的 code。 通常我们省略保留字 then 。若想在一行内写出完整的 if 式,则必须以 then 隔开条件式和程式区块。如下所示:
if a == 4 then a = 7 end实例
#!/usr/bin/ruby # -*- coding: UTF-8 -*- x=1 if x > 2 puts "x 大于 2" elsif x <= 2 and x!=0 puts "x 是 1" else puts "无法得知 x 的值" end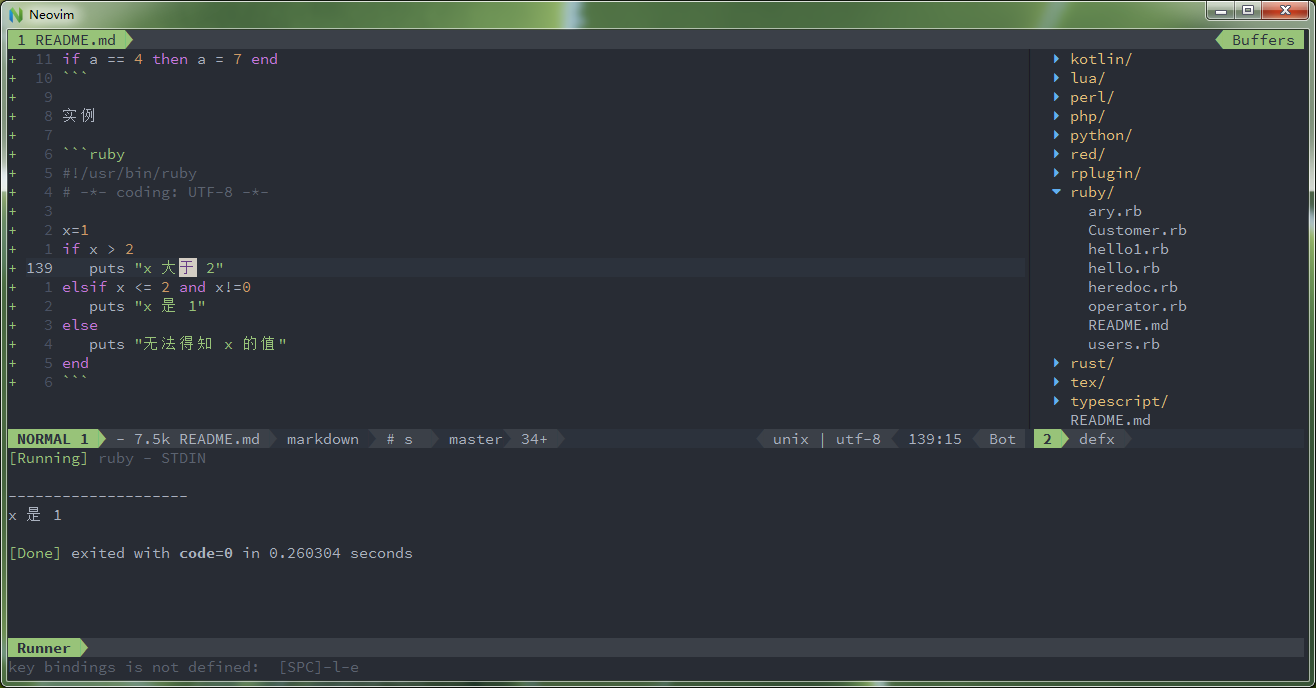
if 修饰符
语法
code if condition如果 conditional 为真,则执行 code。
实例
#!/usr/bin/ruby $debug=1 puts "debug\n" if $debug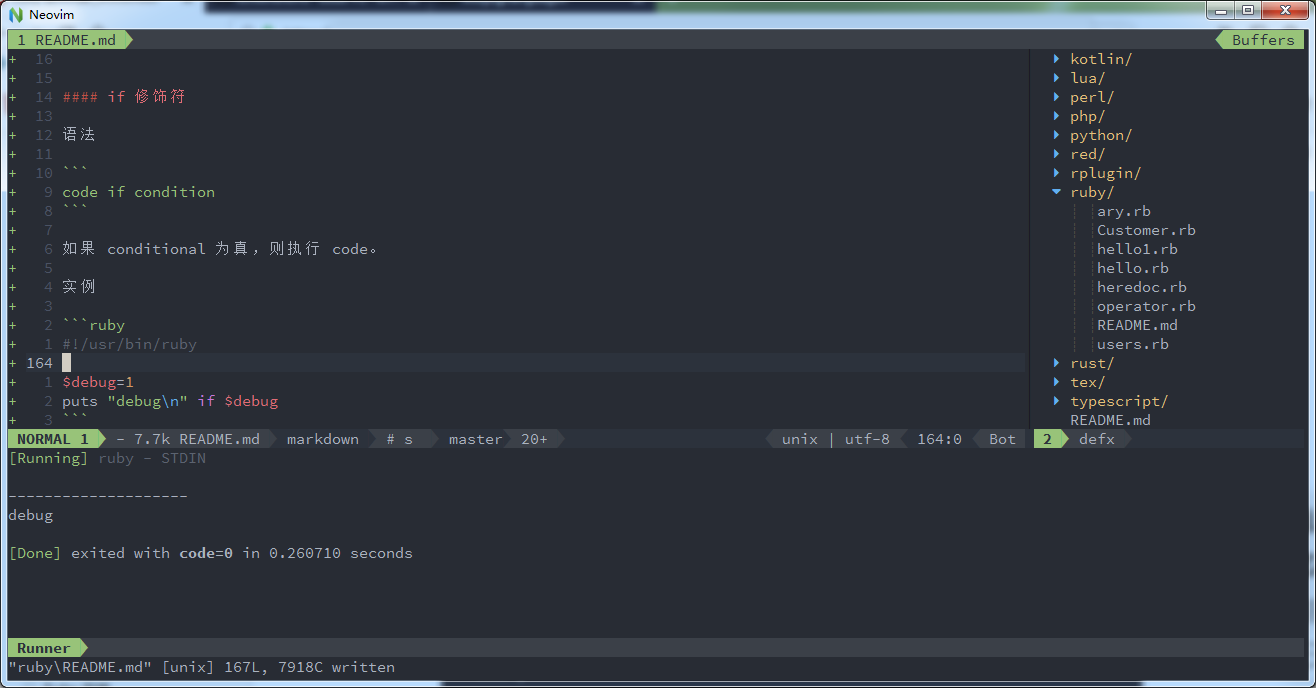
unless 语句
语法
unless conditional [then] code [else code ] endunless 式和 if 式作用相反,即如果 conditional 为假,则执行 code。如果 conditional 为真,则执行 else 子句中指定的 code。
实例
#!/usr/bin/ruby x=1 unless x>2 puts "x 小于 2" else puts "x 大于 2" end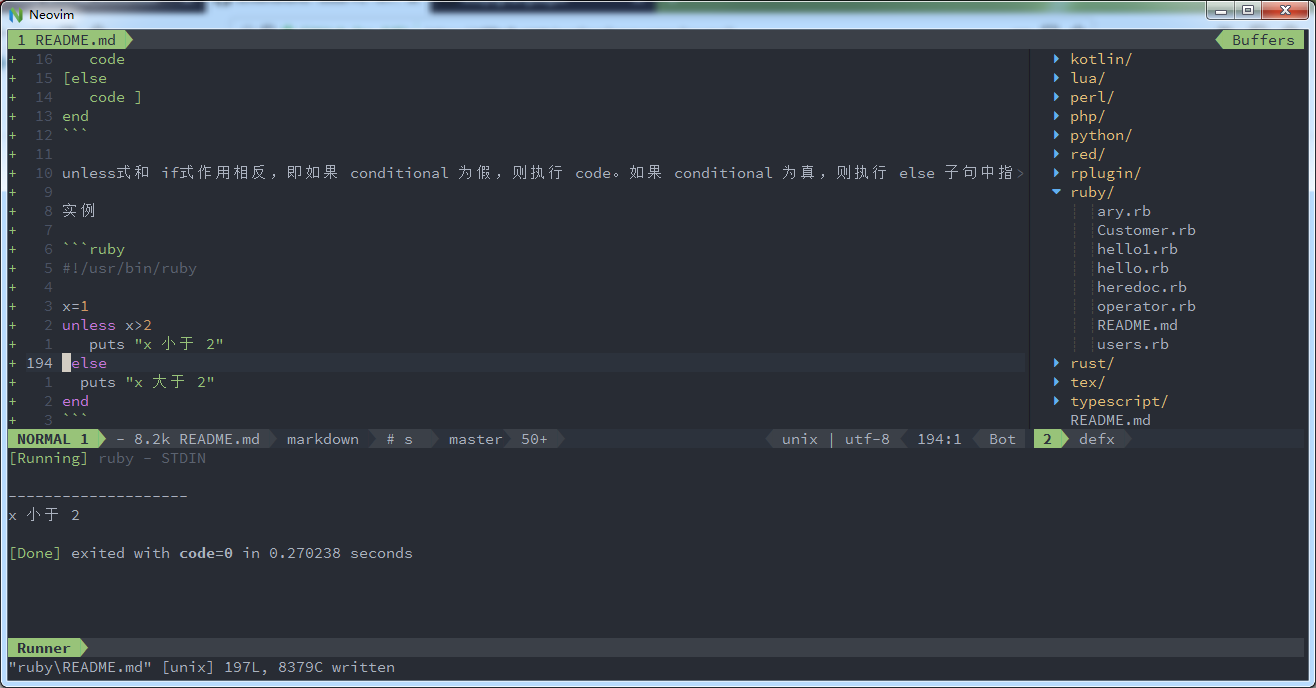
unless 修饰符
语法
code unless conditional如果 conditional 为假,则执行 code。
实例
#!/usr/bin/ruby # -*- coding: UTF-8 -*- $var = 1 print "1 -- 这一行输出\n" if $var print "2 -- 这一行不输出\n" unless $var $var = false print "3 -- 这一行输出\n" unless $var
case 语句
语法
case expression [when expression [, expression ...] [then] code ]... [else code ] endcase 先对一个 expression 进行匹配判断,然后根据匹配结果进行分支选择。
它使用 ===运算符比较 when 指定的 expression,若一致的话就执行 when 部分的内容。
通常我们省略保留字 then 。若想在一行内写出完整的 when 式,则必须以 then 隔开条件式和程式区块。如下所示:
when a == 4 then a = 7 end因此:
case expr0 when expr1, expr2 stmt1 when expr3, expr4 stmt2 else stmt3 end基本上类似于:
_tmp = expr0 if expr1 === _tmp || expr2 === _tmp stmt1 elsif expr3 === _tmp || expr4 === _tmp stmt2 else stmt3 end实例
#!/usr/bin/ruby # -*- coding: UTF-8 -*- $age = 5 case $age when 0 .. 2 puts "婴儿" when 3 .. 6 puts "小孩" when 7 .. 12 puts "child" when 13 .. 18 puts "少年" else puts "其他年龄段的" end
-
Ruby 运算符
算术运算符
算数运算符,顾名思义,常见的加减乘除,还有取余等:
运算符 描述 实例 + 加法 - 把运算符两边的操作数相加 a + b 将得到 30 - 减法 - 把左操作数减去右操作数 a - b 将得到 -10 * 乘法 - 把运算符两边的操作数相乘 a * b 将得到 200 / 除法 - 把左操作数除以右操作数 b / a 将得到 2 % 求模 - 把左操作数除以右操作数,返回余数 b % a 将得到 0 ** 指数 - 执行指数计算 a**b 将得到 10 的 20 次方 puts 1 + 2 puts 1 * 2 puts 2 - 1 puts 2 / 2 puts 11 % 3 puts 4**3比较运算符
假设变量 a 的值为 10,变量 b 的值为 20,那么:
运算符 描述 实例 == 检查两个操作数的值是否相等,如果相等则条件为真。 (a == b) 不为真。 != 检查两个操作数的值是否相等,如果不相等则条件为真。 (a != b) 为真。 > 检查左操作数的值是否大于右操作数的值,如果是则条件为真。 (a > b) 不为真。 < 检查左操作数的值是否小于右操作数的值,如果是则条件为真。 (a < b) 为真。 >= 检查左操作数的值是否大于或等于右操作数的值,如果是则条件为真。 (a >= b) 不为真。 <= 检查左操作数的值是否小于或等于右操作数的值,如果是则条件为真。 (a <= b) 为真。 <=> 联合比较运算符。如果第一个操作数等于第二个操作数则返回 0,如果第一个操作数大于第二个操作数则返回 1,如果第一个操作数小于第二个操作数则返回 -1。 (a <=> b) 返回 -1。 === 用于测试 case 语句的 when 子句内的相等。 (1…10) === 5 返回 true。 .eql? 如果接收器和参数具有相同的类型和相等的值,则返回 true。 1 == 1.0 返回 true,但是 1.eql?(1.0) 返回 false。 equal? 如果接收器和参数具有相同的对象 id,则返回 true。 如果 aObj 是 bObj 的副本,那么 aObj == bObj 返回 true,a.equal?bObj 返回 false,但是 a.equal?aObj 返回 true。 赋值运算符
运算符 描述 实例 = 简单的赋值运算符,把右操作数的值赋给左操作数 c = a + b 将把 a + b 的值赋给 c += 加且赋值运算符,把右操作数加上左操作数的结果赋值给左操作数 c += a 相当于 c = c + a -= 减且赋值运算符,把左操作数减去右操作数的结果赋值给左操作数 c -= a 相当于 c = c - a *= 乘且赋值运算符,把右操作数乘以左操作数的结果赋值给左操作数 c _= a 相当于 c = c _ a /= 除且赋值运算符,把左操作数除以右操作数的结果赋值给左操作数 c /= a 相当于 c = c / a %= 求模且赋值运算符,求两个操作数的模赋值给左操作数 c %= a 相当于 c = c % a **= 指数且赋值运算符,执行指数计算,并赋值给左操作数 c **= a 相当于 c = c ** a 并行赋值
Ruby 也支持变量的并行赋值。这使得多个变量可以通过一行的 Ruby 代码进行初始化。例如:
a = 10 b = 20 c = 30使用并行赋值可以更快地声明:
a, b, c = 10, 20, 30并行赋值在交换两个变量的值时也很有用:
a, b = b, a
-
如何在 Vim 内进行高效的排序
Vim 分别提供了排序函数
sort()、uniq()和排序命令:sort。机遇这两种方式,可以在 Vim 内对文本进行高效的排序。 下面分两部分详细说明下这两种方式的使用方法。排序命令
:sort命令的用法格式如下::[range]sor[t][!] [b][f][i][n][o][r][u][x] [/{pattern}/][range]值得是一个范围,:sort命令会基于这个范围进行排序,当未制定范围时,会对整个文档进行排序。关于[range]的常用方法有下面几种:我们看到
sor[t]最后一个字母t被方括号包围,表示该字母可以省略,即更简单地执行:sor命令。 在:sort命令紧接其后的感叹号!表示是否进行反向排序,不带感叹号则是正向排序,带上则反之。 在:sort命令紧接其后的第一个参数为可选参数,包括b,f,i,n,o,r,u,x。首先,需要了解选项nfxob之间是互斥的,也就是说不可以同时使用这些选项,换句话说。前面的这个五个选项可以和iru这三项组合使用。下面分别说下这些参数的意义:- 带
n则排序基于每行的第一个十进制数 (在{pattern}匹配之后或之内)。数值包含前导的 ‘-‘。 - 带
f则排序基于每行的第一个浮点数。浮点值相当于在文本({pattern}匹配的之后或之内) 上调用 str2float() 函数的结果。仅当 Vim 编译时加入浮点数支持时该标志位才有效。 - 带
x则排序基于每行的第一个十六进制数 (在{pattern}匹配之后或之内)。忽略该数值前的 “0x” 或 “0X”。但包含前导的 ‘-‘。 - 带
o则排序基于每行的第一个八进制数 (在{pattern}匹配之后或之内)。 - 带
b则排序基于每行的第一个二进制数 (在{pattern}匹配之后或之内)。 - 带
u(u 代表 unique 唯一) 则只保留完全相同的行的第一行 (如果同时带i,忽略大小写的区别)。没有这个标志位,完全相同的行的序列会按照它们原来的顺序被保留下来。 注意: 行首和行尾的的空白差异会影响唯一性的判定。
排序函数
Vim 提供两个排序相关的函数
sort()和uniq(),sort()这个函数的用法如下:sort({list} [, {func} [, {dict}]])给定一个 List 经过排序后,返回一个结果,同样也是 List。
sort()这一函数第二个参数可以接受如下几种情况:1或者i: 表示忽略大小写。n:按照数值排序,即使用strtod()解析 List 内的元素,字符串、列表、字典和函数引用均视作 0。f:按照浮点数值来排序,要求给定的 List 每一个选项都是浮点数。- 一个
Funcref变量。这个变量表示的是一个函数,则调用该函数来比较项目,该函数会使用两个项目作为参数,根据返回值确定两个项目关系。 0 表示相等,1 或者更高,表示第一个排在第二个之后,-1 或更小代表第一个排在第二个之前。
- 带
-
(Neo)Vim 插件开发指南
简介
(Neo)Vim 插件开发中文指南,主要包括 Vim 脚本语法、插件开发技巧等。
基本语法
注释
在写脚本时,经常需要在源码里面添加一些注释信息,辅助阅读源码,Vim 脚本注释比较简单,是以
"开头的,只存在行注释,不存在块注释。因此,对于多行注释,需要再每行开头添加"。示例:
" 这是一行注释, let g:helloworld = 1 " 这是在行尾注释变量
在 Vim 脚本里,可以使用关键字
let来申明变量,最基本的方式为:" 定义一个类型是字符串的变量 g:helloworld let g:helloworl = "sss"前面的例子中,是定义一个字符串,Vim 脚本中支持以下几种数据类型:
类型 ID 描述 Number 0 整数 String 1 字符串 Funcref 2 函数指针 List 3 列表 Dictionary 4 字典 Float 5 浮点数 Boolean 6 None 7 Job 8 Channel 9 作用域
Vim 变量存在三种作用域,全局变量、局部变量、和脚本变量。通常,我们以不同的前缀来区别作用域,比如使用
g:表示全局变量,s:表示脚本变量。 在一些特殊情况下,前缀是可以省略的,Vim 会为该变量选择默认的作用域。不同的情况下,默认的作用域是不一样的,在函数内部,默认作用域是局部变量, 而在函数外部,默认作用域是全局变量:let g:helloworld = 1 " 这是一个全局变量, g: 前缀未省略 let helloworld = 1 " 这也是一个全局变量,在函数外部,默认的作用域是全局的 function! HelloWorld() let g:helloworld = 1 " 这是函数内部全局变量 let helloworld = 1 " 这是一个函数内部的局部变量,在函数内部,默认的作用域为局部变量 endfunction前缀 描述 g:全局变量 l:局部变量,只可在函数内部使用 s:脚本变量,只可以在当前脚本函数内使用 v:Vim 特殊变量 b:作用域限定在某一个缓冲区内 w:作用域限定在窗口内部 t:作用域限定在标签内部 此外,在开发 Vim 插件之前,你还需要了解 vimrc 和 Vim 插件的区别。
函数定义
可以使用
function关键字定义函数,可缩写成func或者fn, 格式::fu[nction][!] {name}([arguments]) [range] [abort] [dict] [closure]当使用了参数
closure时,函数可以访问外部的变量或者参数,比如:function! Foo() let x = 0 function! Bar() closure let x += 1 return 1 endfunction return funcref('Bar') endfunction let F = Foo() echo F() " 1 echo F() " 2 echo F() " 3插件的目录结构
在开发插件之前,需要了解下一个插件项目的目录结构是怎样的,以及每一个目录里文件的意义是什么。
插件标准的目录结构为:
autoload/ 自动载入脚本 colors/ 颜色主题 plugin/ 在 Vim 启动时将被载入的脚本 ftdetect/ 文件类型识别脚本 syntax/ 语法高亮文件 ftplugin/ 文件类型相关插件 compiler/ 编译器 indent/ 语法对齐下面,我们来逐一说明下每一个目录的用途:
autoload/
顾名思义,该文件夹下的脚本会在特点条件下自动被载入。这里的特定条件指的是当某一个 autoload 类型的函数被调用,并且 Vim 当前环境下并未定义该函数时。 比如调用
call helloworld#init()时,Vim 会先检测当前环境下是否定义了该函数,若没有,则在autoload/目录下找helloworld.vim这一文件, 并将其载入,载入完成后执行call helloworld#init().plugin/
该目录里的文件将在 Vim 启动时被运行,作为一个优秀的 Vim 插件,应当尽量该目录下的脚本内容。通常,可以将插件的快捷键、命令的定义保留在这个文件里。
ftdetect/
ftdetect 目录里通常存放的是文件类型检测脚本,该目录下的文件也是在 Vim 启动时被载入的。在这一目录里的文件内容,通常比较简单,比如:
autocmd BufNewFile,BufRead *.helloworld set filetype=helloworld以上脚本使得 Vim 在打开以
.helloworld为后缀的文件时,将文件类型设置为helloworld。通常,这个脚本的文件名是和所需要设置的文件类型一样的,上面的例子中文件的名称就是helloworld.vim。syntax/
这一目录下的文件,主要是定义语法高亮的。通常文件名前缀和对应的语言类型相同,比如 Java 的语法文件文件名为
java.vim。 关于如何写语法文件,将在后面详细介绍。colors/
colors 目录下主要存储一些颜色主题脚本,当执行
:colorscheme + 主题名命令时,对应的颜色主题脚本将被载入。比如执行:colorscheme helloworld时,colors/helloworld.vim这一脚本将被载入。compiler/
这一名录里是一些预设的编译器参数,主要给
:make命令使用的。在最新版的 Vim 中可以使用:compiler! 编译器名来为当前缓冲区设定编译器。比如当执行:compiler! helloworld时,compiler/helloworld.vim这一脚本将被载入。indent/
在 indent 目录里,主要是一些语法对齐相关的脚本。
Vim 自定义命令
Vim 的自定义命令可以通过
command命令来定义,比如:command! -nargs=* -complete=custom,helloworld#complete HelloWorld call helloworld#test()紧接
command命令其后的!表示强制定义该命令,即使前面已经定义过了同样名称的命令,也将其覆盖掉。-nargs=*表示,该命令可接受任意个数的参数, 包括 0 个。-nargs的取值有以下几种情况:参数 定义 -nargs=0不接受任何参数(默认) -nagrs=1只接受一个参数 -nargs=*可接收任意个数参数 -nargs=?可接受 1 个或者 0 个参数 -nargs=+至少提供一个参数 -complete=custom,helloworld#complete表示,改命令的补全方式采用的是自定义函数helloworld#complete。-complete可以接受的参数包括如下内容:参数 描述 -complete=augroupautocmd 组名 -complete=bufferbuffer 名称 -complete=behave:behave命令子选项-complete=color颜色主题 -complete=commandEx 命令及参数 -complete=compiler编译器 -complete=cscope:cscope命令子选项-complete=dir文件夹名称 -complete=environment环境变量名称 -complete=event自动命令的事件名称 -complete=expressionVim 表达式 -complete=file文件及文件夹名称 -complete=file_in_pathpath选项里的文件及文件夹名称-complete=filetype文件类型 -complete=function函数名称 -complete=help帮助命令子选项 -complete=highlight高亮组名称 -complete=history:history子选项-complete=localelocale 名称(相当于命令 locale -a的输出)-complete=mapping快捷键名称 -complete=menu目录 -complete=messages:messages命令子选项-complete=optionVim 选项名称 -complete=packadd可选的插件名称补全 -complete=shellcmdshell 命令补全 -complete=sign:sign命令补全-complete=syntax语法文件名称补全 -complete=syntime:syntime命令补全-complete=tagtags -complete=tag_listfilestags, file names are shown when CTRL-D is hit -complete=useruser names -complete=varuser variables -complete=custom,{func}custom completion, defined via {func} -complete=customlist,{func}custom completion, defined via {func} 这里主要解释一些自定义的补全函数,从上面的表格可以看出,有两种定义自定义命令补全函数的方式。
-complete=custom,{func}和-complete=customlist,{func}。这两种区别在与函数的返回值, 前者要求是一个string而后者要求补全函数的返回值是list. 自定义命令补全函数接受三个参数。:function {func}(ArgLead, CmdLine, CursorPos)我们以实际的例子来解释这三个参数的含义,比如在命令行是如下内容时,
|表示光标位置,我按下了<Tab>键调用了补全函数,那么传递给补全函数的三个参数分别是::HelloWorld hello|参数名 描述 ArgLead当前需要补全的部分,通常是光标前的字符串,上面的例子中是指 helloCmdLine指的是整个命令行内的内容,此时是 HelloWorld helloCursorPos指的当前光标所在的位置,此时是 16, 即为 len('HelloWorld hello')下面,我们来看下定义的函数具体内容:
function! helloworld#complete(ArgLead, CmdLine, CursorPos) abort return join(['hellolily', 'hellojeky', 'hellofoo', 'world'] \ "\n") endfunction在上面的函数里,返回的实际上是一个有四行的字符串,Vim 会自动根据
ArgLead来筛选出可以用来补全的选项,并展示在状态栏上。 此时,四行里最后一个world因为开头不匹配ArgLead所以不会被展示在状态栏上,因此补全效果只有三个可选项。
-complete=customlist,{func}这一参数所对应的补全函数,也是接受相同的三个参数,但该函数返回的是一个 list。下面,我们来测试这个函数:
function! helloworld#complete(ArgLead, CmdLine, CursorPos) abort return ['hellolily', 'hellojeky', 'hellofoo', 'world'] endfunction
区别很明显,
customlist补全时不会自动根据ArgLead进行筛选,并且直接补全整个返回的 list,即使列表中有一个world完全与ArgLead(hello)不同, 也会将其直接覆盖。因此,当使用customlist时,需要在函数内根据ArgLead进行筛选,将函数该为如下,就可以得到相同效果了:function! helloworld#complete(ArgLead, CmdLine, CursorPos) abort return filter(['hellolily', 'hellojeky', 'hellofoo', 'world'], 'v:val =~ "^" . a:ArgLead') endfunction-bang参数:
在定义 Vim 自定义命令时,可以通过
-bang参数来申明这个命令接受感叹号。比如:q与:q!。 下面是一个实例:fu! s:hello(bang) if a:bang echom "带有叹号" else echom "不带有叹号" endif endf command! -bang Hello call s:hello(<bang>0)在上面的实例里,函数的参数写法为
<bang>0, 当执行:Hello!时,传递给s:hello这一函数的参数是!0即为1,因此,此时看到打印了”带有叹号“。其实除了写成
<bang>0, 还可以写<bang>1, 甚至是<bang>+ 一个全局变量。比如:let g:hello = 0 fu! s:hello(bang) if a:bang echom "带有叹号" else echom "不带有叹号" endif endf command! -bang Hello call s:hello(<bang>g:hello)