-
如何使用 SpaceVim 的 Job API
因为 Vim8 和 Neovim 实现的 job 函数存在很大的区别,并且使用的方式也是不一样的。在制作插件时,如果需要同时兼容 Vim 和 Neovim 就会存在很大的麻烦。因此,在 SpaceVim 中,实现了一个
job API,使用示例如下:let s:JOB = SpaceVim#api#import('job') let s:command = ['echo', 'hello world'] function! s:stdout(id, data, event) " the data is a list of string for line in a:data echo line endfor endf call s:JOB.start(s:command, { \ 'on_stdout' : function('s:stdout'), \ } \ )这个 API 的实现,参考了 neovim job 的模型。支持如下参数:
on_stdouton_stderron_exit
-
使用 Vim 作为聊天客户端
目前,使用较多的聊天室是 SpaceVim 的 gitter 聊天室,但是这个平台网页访问比较慢。 因此做了vim-chat,可以在 Vim/Neovim 里面快速打开聊天室进行沟通。

如果有兴趣的,可以自行尝试。这个插件目前开发是在 spacevim 的主仓库,自动更新独立仓库,因此有两种使用方式。你可以在 spacevim 里启用 chat 模块,也可以单独安装vim-chat插件。
-
下载安装winrar,并激活去广告
下载
在 winrar官网(https://www.rarlab.com/download.htm)下载,并安装。
激活
在winrar目录新建
rarreg.key文件,输入以下内容并保存:RAR registration data wncn Unlimited Company License UID=1b064ef8b57de3ae9b52 64122122509b52e35fd885373b214a4a64cc2fc1284b77ed14fa20 66ebfca6509f9813b32960fce6cb5ffde62890079861be57638717 7131ced835ed65cc743d9777f2ea71a8e32c7e593cf66794343565 b41bcf56929486b8bcdac33d50ecf7739960627351a9ef03353a0e 592b327cd80645472f0ee622d1915028a9e05298e593db36384f0f f46afd5fed9b0bd095d1788266b81494b976f78fb1c551ca60a054 b17ad853ab902058b42c6887e1b3d40e0b45abf37de02106056887去广告
-
下载 ResourceHacker.exe, 运行该工具打开winrar安装目录内的
winrar.exe文件: -
定位到String Table(字符串)
- 定位并打开80:2052
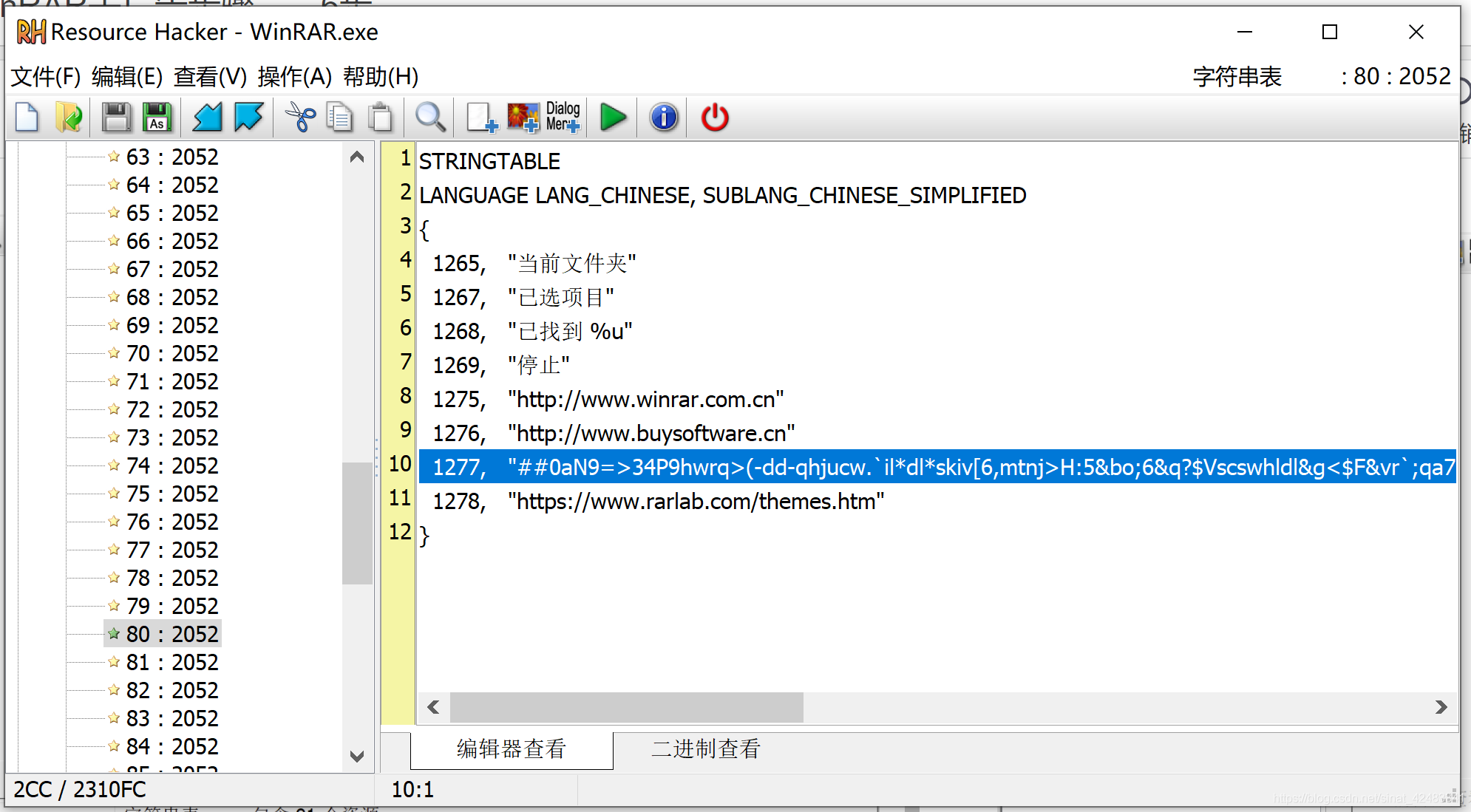
- 删除1277所在整行,点击运行,然后保存。
-
-
在 SpaceVim 中启自动保存
使用 Vim 有一段时间了,SpaceVim 也陆续出了好几个版本。自动保存这个功能一直没有加上,其实并不是没有这个需求,而是没有找到合适的逻辑去实现。最新版SpaceVim新增了自动保存的功能,当然这一功能默认是关闭的。下面来简单介绍一下如何启用自动保存功能。
前因
再使用Vim编辑代码时,经常会出现无意间关闭了Vim,或者各种插件问题导致Vim不能正常工作。忘记保存文件而导致文件编辑内容丢失。不知道大家有没有遇到过,我自己时遇到过好多次。最近,刚刚用上win11,发现office左上角自带了一个自动保存按钮。突然脑洞大开,是时候给SpaceVim也增加这一功能了。
再网上搜索了vim自动保存,发现有不少的插件提供这一功能,总的来说有如下两种逻辑:
1、将文件定期保存到指定的备份文件夹,比如~/.vim/backup
2、定期执行:w命令。
我更倾向于后者。
基本配置
自动保存功能,包含在edit模块里面,可以通过如下配置进行设置:
[[layers]] name = 'edit' autosave_timeout = 300000 autosave_events = ['InsertLeave', 'TextChanged'] autosave_all_buffers = false目前
edit模块支持如下配置选项:autosave_timeout: 设置自动保存的时间间隔,默认是0,表示未开启定时自动保存。这个选项设定的值需要是毫秒数,并且需要小于100*60*1000 (100 分钟) 且 大于1000(1分钟)。比如设定成每隔5分钟自动保存一次:[[layers]] name = 'edit' autosave_timeout = 300000autosave_events: 设定自动保存依赖的Vim事件,默认是空表。比如需要在离开插入模式时或者内容改变时自动保存:[[layers]] name = 'edit' autosave_events = ['InsertLeave', 'TextChanged']autosave_all_buffers: 设定是否需要保存所有文件,默认是只保存当前编辑的文件,如果该选项设定成true则保存所有文件。[[layers]] name = 'edit' autosave_all_buffers = trueautosave_location: 设定保存文件的位置,默认为空,表示保存为原始路径。也可以设定成一个备份文件夹,自动保存的文件保存到指定的备份文件夹里面,而不修改原始文件。[[layers]] name = 'edit' autosave_location = '~/.cache/backup/'
-
Window 7 下安装 nodejs
安装 nodejs
在 Windows 下使用
scoop install nodejs后,发现安装的是 nodejs16,运行提示:无法定位程序输入点GetHostNameW于动态链接库WS2_32.dll上。估计是版本太新,系统不兼容,尝试
scoop uninstall nodejs和scoop install nodejs-lst, 之后运行还是这鬼样子。google搜了一圈,没找到合适的解释。直接:scoop uninstall nodejs-lst scoop install nodejs11
-
配置 zig 的 Vim 开发环境
安装zig语言
我使用的是 Win7 操作系统,从官网下载最新版 zig-windows-x86_64-0.7.1+dfacac916.zip,解压后,发现:

zig 目录下只有一个
zig.exe命令,没有其他的了,这就简单了,直接把这个目录加 PATH 就行, 因为我使用的是 SpaceVim,不需要修改系统环境变量,直接载入 lang#zig 模块。[[layers]] name = 'lang#zig'在启动函数加一句:
let $PATH .= ';D:\zig'完成以上的步骤,基本上可以在 Vim 里面使用 zig 语言相关命令了。
基本运行
在 SpaceVim 里面,运行当前 zig 文件的快捷键是
SPC l r, 这个快捷键实际上是异步运行zig run加上当前文件名。
第一次运行,发现时间是9秒,不知道为什么会这么慢,但是后来的时间都是 0.14 秒左右,可能跟我的电脑有关,比较老了。
语言语法
基本环境搭建好了,那么就是开始学习基本语法了,瞅了一眼官方文档,发现有一些内容跟 rust 很像,不过总体来说,感觉语法还是有点复杂。
代码格式化
zig 命令提供了一个 zig fmt 的子命令,想测试下如何格式化代码,执行直接报错,zig run 没问题:

这种奇葩问题不该只有我一个人遇到吧,于是谷歌搜了一波,发现两个 github 的 issue:#725,#4605
Github issue 已开,等坑被填了再来试试: #7654