-
介绍我的新插件 gfr.vim
今天向大家分享一个我刚写的 Vim 插件 gfr.vim。名字取自三个词语缩写:Grep, Filter, Replace。顾名思义,这个插件提供的功能包括文本搜索、结果筛选以及文本替换功能。
为什么要开发 gfr.vim
Vim 文本搜索的插件已经非常多了,我自己也使用过很多种插件。比如:
ack.vim、ag.vim、grepper.vim等等。这些插件都提供了类似的功能,即为搜索制定的文字,并将结果输出到 Vim 的 quickfix window。 甚至,我之前还制作过一款实时异步搜索,并展示搜索结果的插件 flygrep.vim。但是以上这些插件仅仅支持搜索指定文本的结果,不具备二次检索和替换的功能。
gfr.vim 的功能特点
异步执行
这个插件中,我比较常用的命令是
:Grep。实际上,Vim 本身也有:grep和:vimgrep命令,功能是相同的,都是执行搜索命令,并且把搜索的结果展示在 quickfix 窗口内。 但是 Vim 自带的:grep和:vimgrep命令是单线程的,如果搜索的文件夹内内容非常多会卡住当前 Vim 的操作界面,体验不是很好。兼容 Vim/Neovim
Vim 和 Neovim 的一些内置函数还是有些差异的,而
gfr.vim集成了 SpaceVim 的 API,可以同时兼容 Vim 和 Neovim。弹窗消息界面
gfr.vim使用了 SpaceVim 的 notify API,对于一些插件通知消息,在 Vim 右上方使用浮窗提示。如何安装
和其他常用插件一样,你可以使用任意一个插件管理器来安装,比如使用 plug.vim:
Plug 'wsdjeg/gfr.vim'在插件列表添加上面这段即可,启动 Vim 后执行
:PlugInstall。如何使用
gfr.vim提供了如下命令::Grep: 搜索指定的文本,该命令后面的参数即为需要搜索的文本,比如:Grep hello指的就是搜索hello。如果直接调用:Grep,并且不带任何参数,那么会弹出一个输入框,可供输入需要搜索的文本。:Filter:检索上一次搜索的结果,可以理解为二次筛选。对于上一次搜索或者检索的结果,进行再一次的筛选。:GrepSave:将当前的搜索结果保存至命名标签,以便于快速访问。:GrepResum:使用:GrepResum 标签名可以快速打开以往的搜索结果:Replace:对搜索到的结果执行文本替换
后续计划
目前,这个插件只支持
grep命令,后续计划增加ag、rg等命令支持。
-
将微信朋友圈移至静态网站
五一期间花了一点点时间将微信朋友圈“移植”到博客相册,今天抽空整理了下这个过程,并记录。
归因
微信朋友圈14年左右开始使用,至今已经十年了,出于以下原因放弃:
- 不开放,只能微信里面,其他地方无法查看。
- 图片损伤,上传到朋友圈的照片会自动压缩,无法存储原图。
- 审查机制,不过多解释,虽然不喜欢讨论政治等敏感话题
- 永久存储,不确定哪一天微信会关闭
- 无法发链接,格式太受限
- 无法更新,过往内容无法更新
我需要的“朋友圈”
- 开放的,输入网址即可访问,而非仅限于在微信内
- 内容自由的,自己可控的
- 安全的,内容存储于私密仓库,安全,易备份。
- 格式自由,虽然不需要富文本那么花俏,但是简单的 markdown 语法还是需要的
- 可更新
- 日志独立,可关联
博客相册生成
最起初,只有三五个相册的时候,相册页面的内容是纯手工写的。后来,当把朋友圈老照片都转移过来后,手工操作的话就不合适了。
因为相册的内容比较简单:
{日期} {context} {gallery} {location}因此,基于
dev#autodocAPI 写了一个脚本:let s:AUTODOC = SpaceVim#api#import('dev#autodoc') let s:AUTODOC.autoformat = 0 function! Gengallery() abort let s:AUTODOC.begin = '^<!-- wsdjeg.net gallery start -->$' let s:AUTODOC.end = '^<!-- wsdjeg.net gallery end -->$' let s:AUTODOC.content_func = function('s:generate_gallery') call s:AUTODOC.update() endfunction function! s:generate_gallery() abort let content = [] call extend(content, s:gallery_list()) let content += [''] return content endfunction function! s:gallery_list() abort let text = [] let gallery_dirs = globpath('docs/uploads', '*', 1, 1) let previous_t = '' for gpath in gallery_dirs if empty(previous_t) || matchstr(gpath, '\d\+') !=# previous_t call extend(text, s:dir_to_g(gpath), 0) let previous_t = matchstr(gpath, '\d\+') endif endfor return text endfunction function! s:dir_to_g(d) abort let t = [] let y = str2nr(matchstr(a:d, '\d\d\d\d')) let m = str2nr(matchstr(a:d, '\d\d\d\d\zs\d\d')) let d = matchstr(a:d, '\d\d\d\d\d\d\zs\d\d') call add(t, '### ' . y . '年' . m . '月' . (empty(d) ? '' : d . '日')) call add(t, '') " 如果存在 text.txt 文件,读取内容,写入文字 if filereadable(a:d . '/text.txt') call extend(t, readfile(a:d . '/text.txt')) call add(t, '') endif call add(t, '{% include image-gallery-nofilename.html folder="' . substitute(a:d[5:], '\', '/', 'g') . '" %}') call add(t, '') " 如果存在 location 文件,读取内容,写入地址 if filereadable(a:d . '/location') call add(t, '> <i class="fa fa-map-marker"></i> ' . readfile(a:d . '/location')[0]) call add(t, '') endif return t endfunction
-
五一假期·苏州一日游
转眼间毕业已经十三年了,错过了大学同学毕业十年聚会,挺可惜的。一直想找时间回学校看看。
今天正好带着家人回学校转转,本以为假日期间在学校不会看到太多的人。但是到了之后发现,有很多都是带着小孩子到学校里面拍照、画画。
午饭选的是“桃花源记”,进川菜馆吃苏帮菜,有点失误了。
下午去了“诚品书店”,以前空闲的时候过去,书店里人很少,很安静。是个不错的看书的地方,今天人有点太多了,有点赶集的味道。
下一站去了圆融天幕,可惜不是晚上,没有看到夜景。
开车来到了平江路,一眼望去乌泱泱的人,只能放弃这一站了,还有苏州地标大秋裤也没来得及去看,期待下次吧。
-
《长空之王》观后感
今天是大悦城开业活动的最后一天,以前这个地方叫博大摩登。原先人气一点也不旺,但是这次过来感觉确实很热闹。
中午尝了一下新白鹿,一家不错的杭州菜。晚上看了一部电影,《长空之王》。实际上本来前天就想看了,周五晚上回来后在融创茂吃了个“等鱼柒·豆花烤鱼”,已经不记得是第几次吃这家了,小朋友似乎挺爱吃的。 完了本来想去看看电影,奈何时间太晚了,只能早早回去休息。
第一次了解到试飞员这一高危的职业,希望每一次试飞都可以安全落地。
看似和平的年代,实际上有很多人在背后默默付出,默默守护。
电影中穿插着各种家庭的元素,有父母、有老婆孩子,虽然不舍,但是还是默默支持,默默承受着。
张大队那句“做为军人,性命加使命才是生命”真的太贴切了,看完整个人都久久的沉浸在这样的敬佩、感动和自豪中,致敬这样一群默默守护我们的人!
-
Neovim lua bindeval 解决方案
最近在改写插件 tagbar 的日志系统,采用 SpaceVim 内置的日志插件。但是在调用 debug 函数时发现日志一直无法写入。
代码逻辑非常简单,lua 文件逻辑:
lua/spacevim/logger.lualocal M = {} function M.test() local derive = { _debug_mode = false, } function derive.debug(msg) if derive._debug_mode then print(msg) end end return derive end return Mvim script 这边只定义了一个函数:
autoload/testl.vimfunction! testl#test() abort return luaeval('require("testluaeval").test()') endfunction测试步骤:
let tlog = testl#test() let tlog._debug_mode = v:true call tlog.debug('hello')运行到此处发现,消息并没有被打印。于是在 neovim 仓库提交了issue。得到的回复是,目前 neovim 还不支持 bindeval,但是支持 closures。
因此逻辑上做了如下改动:
lua/spacevim/logger.lualocal M = {} function M.test() local derive = { _debug_mode = false, } function derive.debug(msg) if derive._debug_mode then print(msg) end end function derive.start_debug() derive._debug_mode = true end function derive.stop_debug() derive._debug_mode = false end return derive end return Mvim script 这边只定义了一个函数:
autoload/testl.vimfunction! testl#test() abort return luaeval('require("testluaeval").test()') endfunction测试步骤:
let tlog = testl#test() call tlog.start_debug() call tlog.debug('hello')通过以上的改动,测试步骤可以达到预期效果。
-
《忠犬八公》观后感
结束了一周的出差,周五到家后,习惯性的看看有什么好看的电影上映。正好看到《忠犬八公》上映。
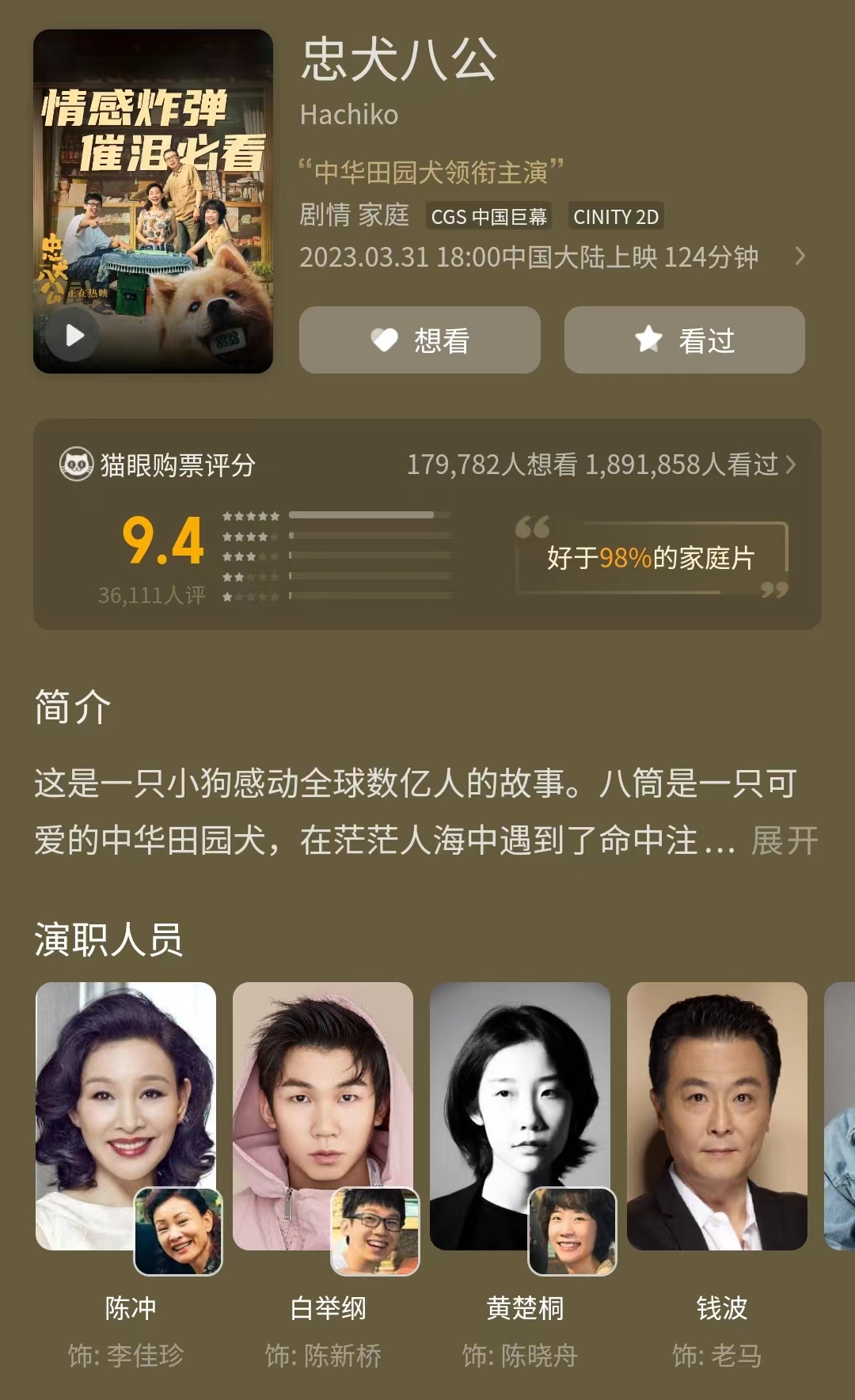
刚开始还有一些疑惑,因为这部电影我记得很早以前就看过。仔细看来原来是大陆拍的,以前看的另外一个版本。
晚饭后,一家人一起去,正好赶上 7:20 这场。
可能是因为以前看过了,对剧情也大概有了心理预知,所以剧情上倒没有什么特别大的感触。
但是期间一些细节也让我感触很多:
- 教授第一次发飙讲的那段话,其实也很在理。人生匆匆几十年(现在已经过一小半了),没有什么比喜欢更重要。
- 教授妻子嘴上太伤人,但是其实内心还是很关心教授和八筒,也许她喜欢八筒只是爱屋及乌。
- 教授送儿子这段,父亲和母亲表达爱的方式还是有区别的。突然让我想到父亲送我上大学的那天,临走时,我秦楚地看到,父亲的眼睛很红。也是,以往都是离家很近上学。上了大学之后,包括现在工作了以后,回去的机会太少了。
- 儿子一直被误会在瞎折腾,倔强的坚持着他人看不懂的东西,最后实现自己的目标时开心。想想也是,很多时候,自己觉得对即可。
- 而最让我感触的,还是回忆结束后最后一段,看到满屋的报纸后,可以想象“八筒”日复一日的等了多久。
小狗的想法要比人类简单太多太多了,他的忠诚值得善待!