-
开始学习 Rust
写在前面
rust 这门语言刚出来时,非常火,当时还没有中文的教程,官方仅有的一篇英文教程和examples。 于是对着英文教程,靠着自己蹩脚的英语啃了一遍。但是过了这么久,并且期间没在使用这门语言, 已经基本忘记了,唯一记得的就是 rust 里面提出了一个叫做“借”的概念,当时被绕了很久。
rust的安装非常简单,在windows下,只需要下载 rustup-init.exe 后运行安装即可。
1. 第一个程序
main.rs:fn main() { println!("Hello, world!"); }运行非常简单,使用
rustc main.rs即可编译出一个可执行运行文件。println 的一些用法:
fn main() { println!("{}, {}!", "Hello", "world"); // Hello, world! println!("{0}, {1}!", "Hello", "world"); // Hello, world! println!("{greeting}, {name}!", greeting="Hello", name="world"); // Hello, world! let y = String::from("Hello, ") + "world!"; println!("{}", y); // Hello, world! }2. 基本语法
2.1 注释
rust 的注释有两种,单行注释,和快注释:
fn main() { // 单行注释 println!("hello"); // 行尾注释 /* 块注释 */ }2.2 变量
rust 中包括局部变量和全局变量,默认都是局部变量,并且都是不可变变量,可以使用
mut标记为可变变量。- 局部变量
let a; // 声明变量,但并不赋值 let b = true; // 声明 bool 变量,并赋值 let c: bool = true; let (x, y) = (1, 2); a = 122; let mut d = 1; d = 20;- 全局变量
rust中使用
static关键字申明全局变量,全局变量的生命周期是整个程序,必须显式标明类型,不支持类型推导;// 不可变静态变量 static N: i32 = 64; // 可变静态变量 static mut M: i32 = 10;- 常量
常量的申明使用
const,和全局变量一样,生命周期也是整个程序。const N: i32 = 10;2.3 函数
函数使用
fn来申明,例如:fn test_func() { println!("hi"); }函数的参数需要指定类型,例如:
fn test_func(a: i32, b: i32) { println!("the sum is:{}", a + b); }函数的返回值默认是
(),如果需要有返回值,需要在函数签名里使用->指定:fn test_func(a: i32, b: i32) -> i32 { println!("the sum is:{}", a + b); a + b // 等同于 return a + b; }Rust 是基于表达式的语言,程序的最后一句话需要省略分号,作为返回值, 当然 rust 也支持使用 return 提前返回,但是需要加上分号。
rust是一个基于表达式的语言,不过它也有语句。 rust只有两种语句:声明语句和表达式语句,其他的都是表达式。 基于表达式是函数式语言的一个重要特征,表达式总是返回值。
可以利用元组(tuple)返回多个值:
fn plus_one(a: i32) -> (i32, i32) { (a, &a + 1) } fn main() { let (add_num, result) = plus_one(10); println!("{} + 1 = {}", add_num, result); // 10 + 1 = 11 }函数指针也可以作为变量使用
fn hello() { println!("hello world!"); } fn main() { let b = hello; b(); }- 高阶函数
Rust 还支持高阶函数 (high order function),允许把闭包作为参数来生成新的函数:
fn add_one(x: i32) -> i32 { x + 1 } fn apply<F>(f: F, y: i32) -> i32 where F: Fn(i32) -> i32 { f(y) * y } fn factory(x: i32) -> Box<Fn(i32) -> i32> { Box::new(move |y| x + y) } fn main() { let transform: fn(i32) -> i32 = add_one; let f0 = add_one(2i32) * 2; let f1 = apply(add_one, 2); let f2 = apply(transform, 2); println!("{}, {}, {}", f0, f1, f2); let closure = |x: i32| x + 1; let c0 = closure(2i32) * 2; let c1 = apply(closure, 2); let c2 = apply(|x| x + 1, 2); println!("{}, {}, {}", c0, c1, c2); let box_fn = factory(1i32); let b0 = box_fn(2i32) * 2; let b1 = (*box_fn)(2i32) * 2; let b2 = (&box_fn)(2i32) * 2; println!("{}, {}, {}", b0, b1, b2); let add_num = &(*box_fn); let translate: &Fn(i32) -> i32 = add_num; let z0 = add_num(2i32) * 2; let z1 = apply(add_num, 2); let z2 = apply(translate, 2); println!("{}, {}, {}", z0, z1, z2); }- where 关键字的使用
约束的trait增加后,代码看起来就变得诡异了,这时候需要使用where从句:
use std::fmt::Debug; fn foo<T: Clone, K: Clone + Debug>(x: T, y: K) { x.clone(); y.clone(); println!("{:?}", y); } // where 从句 fn foo<T, K>(x: T, y: K) where T: Clone, K: Clone + Debug { x.clone(); y.clone(); println!("{:?}", y); } // 或者 fn foo<T, K>(x: T, y: K) where T: Clone, K: Clone + Debug { x.clone(); y.clone(); println!("{:?}", y); }- 发散函数
发散函数(diverging function)是rust中的一个特性。发散函数不返回,它使用感叹号!作为返回类型表示:
fn main() { println!("hello"); diverging(); println!("world"); } fn diverging() -> ! { panic!("This function will never return"); }2.4 基本数据类型
- 布尔值(bool)
- 字符(char)
- 有符号整型(i8, i16, i32, i64, i128)
- 无符号整型(u8, u16, u32, u64, u128)
- 指针大小的有符号/无符号整型(isize/usize,取决于计算机架构,32bit 的系统上,isize 等价于i32)
- 浮点数(f32, f64)
- 数组(arrays)
数组(arrays)的长度是可不变的,动态/可变长数组可以使用 Vec (非基本数据类型)。
- 元组(tuples),由相同/不同类型元素构成,长度固定。
元组的长度也是不可变的,更新元组内元素的值时,需要与之前的值的类型相同。
- 切片(slice),指向一段内存的指针。
切片并没有拷贝原有的数组,只是指向原有数组的一个连续部分,行为同数组。访问切片指向的数组/数据结构,可以使用&操作符。
let a: [i32; 4] = [1, 2, 3, 4]; let b: &[i32] = &a; // 全部 let c = &a[0..4]; // [0, 4) let d = &a[..]; // 全部 let e = &a[1..3]; // [2, 3] let e = &a[1..]; // [2, 3, 4] let e = &a[..3]; // [1, 2, 3]- 字符串(str)
在 Rust 中,str 是不可变的静态分配的一个未知长度的UTF-8字节序列。 &str 是指向该字符串的切片。
let a = "Hello, world!"; //a: &'static str let b: &str = "你好, 世界!"; // 多行字符串 let a = "line one line two"; // 字符串转义 let a = "line one\nline two" // 也可以在字符串字面量前加上r来避免转义 let a = r"line one\nline two"Rust的数组是被表示为
[T;N]。其中N表示数组大小,并且这个大小一定是个编译时就能获得的整数值,T表示泛型类型,即任意类型。我们可以这么来声明和使用一个数组:let a = [8, 9, 10]; let b: [u8;3] = [8, 6, 5]; print!("{}", a[0]);和Golang一样,Rust的数组中的N(大小)也是类型的一部分, 即
[u8; 3] != [u8; 4]。这么设计是为了更安全和高效的使用内存,当然了, 这会给第一次接触类似概念的人带来一点点困难,比如以下代码。fn show(arr: [u8;3]) { for i in &arr { print!("{} ", i); } } fn main() { let a: [u8; 3] = [1, 2, 3]; show(a); let b: [u8; 4] = [1, 2, 3, 4]; show(b); }以上代码编译会报错,因为
show(b);传入的参数类型是[u8, 4], 但是show(arr: [u8, 3])这个函数签名只接受[u8,3]。因此可以使用切片(Slice),一个Slice的类型是
&[T]或者&mut [T], 因此以上代码可以改为:fn show(arr: &[u8]) { for i in arr { print!("{} ", i); } println!(""); } fn main() { let a: [u8; 3] = [1, 2, 3]; let slice_a = &a[..]; show(slice_a); let b: [u8; 4] = [1, 2, 3, 4]; show(&b[..]); }字符串切片&str指向的字符串是静态分配的,在 Rust 中,有另一个堆分配的, 可变长的字符串类型String(非基本数据类型)。通常由字符串切片&str通过 to_string() 或 String::from() 方法转换得到。
let s1 = "Hello, world!".to_string(); let s2 = String::from("Hello, world!");- 函数(functions)
函数指针也是基本数据类型,可以赋值给其他的变量
2.5 操作符
- 一元操作符
顾名思义,一元操作符是专门对一个Rust元素进行操纵的操作符,主要包括以下几个:
-: 取负,用于数值类型。*: 解引用,这是一个很有用的符号,和Deref(DerefMut)这个trait关联密切。!: 取反。&和&mut: 租借,borrow。向一个owner租借其使用权,分别是租借一个只读使用权和读写使用权。
二元操作符
- 算数操作符
算数运算符都有对应的trait的,他们都在
std::ops下:+: 加法。实现了std::ops::Add。-: 减法。实现了std::ops::Sub。*: 乘法。实现了std::ops::Mul。/: 除法。实现了std::ops::Div。%: 取余。实现了std::ops::Rem。
// 包括: + - * / % let a = 5; let b = a + 1; //6 let c = a - 1; //4 let d = a * 2; //10 let e = a / 2; //2 not 2.5 let f = a % 2; //1 let g = 5.0 / 2.0; //2.5- 比较运算符
比较运算符其实也是某些trait的语法糖啦, 不同的是比较运算符所实现的trait只有两个
std::cmp::PartialEq和std::cmp::PartialOrd// == = != < > <= >= let a = 1; let b = 2; let c = a == b; //false let d = a != b; //true let e = a < b; //true let f = a > b; //false let g = a <= a; //true let h = a >= a; //true let i = true > false; //true let j = 'a' > 'A'; //true- 逻辑运算符
// ! && || let a = true; let b = false; let c = !a; //false let d = a && b; //false let e = a || b; //true // rust 的逻辑运算符是惰性boolean运算符 // @question 什么是惰性boolean运算符- 位运算符
和算数运算符差不多的是,位运算也有对应的trait。
&: 与操作。实现了std::ops::BitAnd。|: 或操作。实现了std::ops::BitOr。^: 异或。实现了std::ops::BitXor。<<: 左移运算符。实现了std::ops::Shl。>>: 右移运算符。实现了std::ops::Shr。
// & | ^ << >> let a = 1; let b = 2; let c = a & b; //0 (01 && 10 -> 00) let d = a | b; //3 (01 || 10 -> 11) let e = a ^ b; //3 (01 != 10 -> 11) let f = a << b; //4 (左移 -> '01'+'00' -> 100) let g = a >> a; //0 (右移 -> o̶1̶ -> 0)- 赋值运算符
let mut a = 2; a += 5; //2 + 5 = 7 a -= 2; //7 - 2 = 5 a *= 5; //5 * 5 = 25 a /= 2; //25 / 2 = 12 not 12.5 a %= 5; //12 % 5 = 2 a &= 2; //10 && 10 -> 10 -> 2 a |= 5; //010 || 101 -> 111 -> 7 a ^= 2; //111 != 010 -> 101 -> 5 a <<= 1; //'101'+'0' -> 1010 -> 10 a >>= 2; //101̶0̶ -> 10 -> 2- 类型转换运算符: as
let a = 15; let b = a / 2.0; //7.5 let b = (a as f64) / 2.0; //7.5- 借用(Borrowing)与解引用(Dereference)操作符
Rust 引入了所有权(Ownership)的概念,所以在引用(Reference)的基础上衍生了借用(Borrowing)的概念,所有权概念不在这里展开。
简单而言,引用是为已存在变量创建一个别名;获取引用作为函数参数称为借用;解引用是与引用相反的动作,目的是返回引用指向的变量本身。
// 引用/借用: & &mut fn main() { let s1 = String::from("hello"); let len = calculate_length(&s1); println!("The length of '{}' is {}.", s1, len); // The length of 'hello' is 5. } fn calculate_length(s: &String) -> usize { // 获取引用作为函数参数称为借用 s.len() }// 解引用: * fn main() { // 获取v的第2个元素的可变引用,并通过解引用修改该元素的值。 let v = &mut [1, 2, 3, 4, 5]; { let third = v.get_mut(2).unwrap(); *third += 50; } println!("v={:?}", v); // v=[1, 2, 53, 4, 5] }2.6 流程控制
- if - else if - else
let team_size = 7; if team_size < 5 { println!("Small"); } else if team_size < 10 { println!("Medium"); } else { println!("Large"); } // 条件块中有返回值时,类型需要一致,可替代C语言的三目运算符 let is_below_eighteen = if team_size < 18 { true } else { false };- match
可替代C语言的switch case。
let tshirt_width = 20; let tshirt_size = match tshirt_width { 16 => "S", // check 16 17 | 18 => "M", // check 17 and 18 19 ... 21 => "L", // check from 19 to 21 (19,20,21) 22 => "XL", _ => "Not Available", }; println!("{}", tshirt_size); // L_表示匹配剩下的任意情况。match 的一些其他用法:
let num = 8; match num { 13 => println!("正确"), 3|4|5|6 => println!("3 或 4 或 5 或 6" ), 14...20 => println!("14..20"), // ... 表示一个范围,可以是数字, `1 ... 10` 也可以是字母 `'a' ... 'z'` _=> println!("不正确"), } let pair = (0, -2); match pair { (0, y) => println!("y={}", y), (x, 0) => println!("x={}", x), _ => println!("default") } // 配合 if 使用 match num { x if x != 20 => println!("14..20"), _=> println!("不正确"), } // 后置套件 let x = 4; let y = false; match x { 4 | 5 if y => println!("yes"), _ => println!("no"), } // 绑定变量 match num { 13 => println!("正确"), 3|4|5|6 => println!("3 或 4 或 5 或 6" ), n @ 14...20 => println!("{}", n), _=> println!("不正确"), }- while
let mut a = 1; while a <= 10 { println!("Current value : {}", a); a += 1; // Rust不支持++/--自增自减语法 }- loop
相当于
while truelet mut a = 0; loop { if a == 0 { println!("Skip Value : {}", a); a += 1; continue; } else if a == 2 { println!("Break At : {}", a); break; } println!("Current Value : {}", a); a += 1; } // Skip Value : 0 // Current Value : 1 // Break At : 2- for
for a in 0..10 { //(a = 0; a <10; a++) println!("Current value : {}", a); } 'outer_for: for c1 in 1..6 { //set label outer_for 'inner_for: for c2 in 1..6 { println!("Current Value : [{}][{}]", c1, c2); if c1 == 2 && c2 == 2 { break 'outer_for; } // 结束外层循环 } } let group : [&str; 4] = ["Mark", "Larry", "Bill", "Steve"]; for person in group.iter() { println!("Current Person : {}", person); }在 for 表达式中的break ‘outer_for,loop 和 while 也有相同的使用方式。
3. 其他数据类型
3.1 结构体(struct)
和元组(tuple)一样,结构体(struct)支持组合不同的数据类型, 但不同于元组,结构体需要给每一部分数据命名以标志其含义。 因而结构体比元组更加灵活,不依赖顺序来指定或访问实例中的值。
定义结构体
struct User { username: String, email: String, sign_in_count: u64, active: bool, }- 创建实例
let user1 = User { email: String::from("[email protected]"), username: String::from("someusername123"), active: true, sign_in_count: 1, };- 修改某个字段的值
let mut user1 = User { email: String::from("[email protected]"), username: String::from("someusername123"), active: true, sign_in_count: 1, }; user1.email = String::from("[email protected]");- 变量与字段名同名的简写语法
fn build_user(email: String, username: String) -> User { User { email, username, active: true, sign_in_count: 1, } }- 元组结构体(tuple structs)
元组结构体有着结构体名称提供的含义,但没有具体的字段名。在参数个数较少时,无字段名称,仅靠下标也有很强的语义时,为每个字段命名就显得多余了。例如:
struct Color(i32, i32, i32); struct Point(i32, i32); let black = Color(0, 0, 0); let origin = Point(3, 4);struct Point { x: i32 y: i32 } let origin = Point { x: 3 y: 4 }3.2 枚举
- 定义枚举
enum IpAddrKind { V4, V6, }- 使用枚举值
let four = IpAddrKind::V4; fn route(ip_type: IpAddrKind) { } route(four); route(IpAddrKind::V6);- 枚举成员关联数据
enum IpAddr { V4(u8, u8, u8, u8), V6(String), } let home = IpAddr::V4(127, 0, 0, 1); let loopback = IpAddr::V6(String::from("::1"));- 更复杂的例子
enum Message { Quit, // 不关联数据 Move { x: i32, y: i32 }, // 匿名结构体 Write(String), ChangeColor(i32, i32, i32), }- match 控制流
enum Coin { Penny, Nickel, Dime, Quarter, } fn value_in_cents(coin: Coin) -> u32 { match coin { Coin::Penny => { println!("Lucky penny!"); 1 }, Coin::Nickel => 5, Coin::Dime => 10, Coin::Quarter => 25, } }- Option
Option是标准库中定义的一个非常重要的枚举类型。Option 类型应用广泛因为它编码了一个非常普遍的场景, 即一个值要么有值要么没值。对Rust而言,变量在使用前必须要赋予一个有效的值, 所以不存在空值(Null),因此在使用任意类型的变量时,编译器确保它总是有一个有效的值,可以自信使用而无需做任何检查。如果一个值可能为空,需要显示地使用Option
来表示。 Option 的定义如下:
pub enum Option<T> { Some(T), None, }Option
包含2个枚举项: 1) None,表明失败或没有值
2) Some(value),元组结构体,封装了一个 T 类型的值 value
得益于Option,Rust 不允许一个可能存在空值的值,像一个正常的有效值那样工作,在编译时就能够检查出来。Rust显得更加安全,不用担心出现其他语言运行时才会出现的空指针异常的bug。例如:
let x: i8 = 5; // Rust 没有空值(Null),因此 i8只能被赋予一个有效值。 let y: Option<i8> = Some(5); // y 可能为空,需要显示地表示为枚举类型 Option let sum = x + y;尝试将不可能出现无效值的 x:i8 与可能出现无效值的y: Option
相加时,编译器会报错: error[E0277]: the trait bound `i8: std::ops::Add<std::option::Option<i8>>` is not satisfied --> | 5 | let sum = x + y; | ^ no implementation for `i8 + std::option::Option<i8>` |总结一下,如果一个值可能为空,必须使用枚举类型Option
,否则必须赋予有效值。而为了使用Option ,需要编写处理每个成员的代码,当T 为有效值时,才能够从 Some(T) 中取出 T 的值来使用,如果 T 为无效值,可以进行其他的处理,通常使用 match 来处理这种情况。 例如,当y为有效值时,返回x和y的和;为空值时,返回x。
fn plus(x: i8, y: Option<i8>) -> i8 { match y { None => x, Some(i) => x + i, } } fn main() { let y1: Option<i8> = Some(5); let y2: Option<i8> = None; let z1 = plus(10, y1); let z2 = plus(10, y2); println!("z1={}, z2={}", z1, z2); // z1=15, z2=10 }- if let 控制流
match 还有一种简单场景,可以简写为 if let。如下,y有值时,打印和,y无值时,啥事也不做。
fn plus(x: i8, y: Option<i8>) { match y { Some(i) => { println!("x + y = {}", x + i) }, None => {}, } } fn main() { let y1: Option<i8> = Some(5); let y2: Option<i8> = None; plus(10, y1); // x + y = 15 plus(10, y2); }简写为 if let,则是
fn plus(x: i8, y: Option<i8>) { if let Some(i) = y { println!("x + y = {}", x + i); } }如果只使用 if 呢?
fn plus(x: i8, y: Option<i8>) { if y.is_some() { let i = y.unwrap(); // 获得 Some 中的 T 值。 println!("x + y = {}", x + i); } }if let 语句也可以包含 else。
fn plus(x: i8, y: Option<i8>) { if let Some(i) = y { println!("x + y = {}", x + i); } else { println!("y is None"); } } // 等价于 fn plus(x: i8, y: Option<i8>) { match y { Some(i) => { println!("x + y = {}", x + i) }, None => { println!("y is None") }, } }3.3 实现方法和接口(impl & trait)
- 实现方法(impl)
Rust 通过关键字
impl在struct、enum或者trait上实现方法。 关联函数 (associated function) 的第一个参数通常为self参数,有3种变体:self: 允许实现者移动和修改对象,对应的闭包特性为FnOnce。&self: 既不允许实现者移动对象也不允许修改,对应的闭包特性为Fn。&mut self: 允许实现者修改对象但不允许移动,对应的闭包特性为FnMut。
不含self参数的关联函数称为静态方法 (static method)。
struct Rectangle { width: u32, height: u32, } impl Rectangle { fn area(&self) -> u32 { self.width * self.height } } impl Rectangle { fn can_hold(&self, other: &Rectangle) -> bool { self.width > other.width && self.height > other.height } } impl Rectangle { fn square(size: u32) -> Rectangle { Rectangle { width: size, height: size } } } fn main() { let rect1 = Rectangle { width: 30, height: 50 }; let rect2 = Rectangle::square(10); println!( "The area of the rectangle is {} square pixels.", rect1.area() ); println!( "The area of the rectangle is {} square pixels.", rect2.area() ); }与结构体一样,枚举中的元素默认不能使用关系运算符进行比较 (如
==,!=,>=), 也不支持像+和*这样的双目运算符,需要自己实现,或者使用match进行匹配。类似于 lua 里面的 metatables,可以通过实现一些借口函数来实现自定义结构体的运算:
struct User { name:String, age:i32, } impl Eq for User { fn eq(&self, other: User) -> bool { self.age == other.age } }枚举默认也是私有的,如果使用pub使其变为公有,则它的元素也都是默认公有的。 这一点是与结构体不同的:即使结构体是公有的,它的域仍然是默认私有的。 这里的共有/私有仍然 是针对其定义所在的模块之外。此外,枚举和结构体也可以是递归的 (recursive)。
例如我们可以提供一个关联函数,它接受一个维度参数并且同时作为宽和高, 这样可以更轻松的创建一个正方形 Rectangle 而不必指定两次同样的值:
- 实现接口(trait)
trait Summary { fn summarize(&self) -> String; } impl Summary for Rectangle { fn summarize(&self) -> String { format!("{width={}, height={}}", self.width, self.height) } } // 接口也支持继承 trait Person { fn full_name(&self) -> String; } trait Employee : Person { //Employee inherit from person trait fn job_title(&self) -> String; } trait Expat { fn salary(&self) -> f32 } trait ExpatEmployee : Employee + Expat { // 多继承,同时继承 Employee 和 Expat fn additional_tax(&self) -> f64; }定义在特性中的方法称为默认方法 (default method),可以被该特性的实现覆盖。 此外,特性之间也可以存在继承 (inheritance):
trait Foo { fn foo(&self); // default method fn bar(&self) { println!("We called bar."); } } // inheritance trait FooBar : Foo { fn foobar(&self); } struct Baz; impl Foo for Baz { fn foo(&self) { println!("foo"); } } impl FooBar for Baz { fn foobar(&self) { println!("foobar"); } }如果两个不同特性的方法具有相同的名称,可以使用通用函数调用语法 (universal function call syntax):
关于实现特性的几条限制:
- 如果一个特性不在当前作用域内,它就不能被实现。
- 不管是特性还是impl,都只能在当前的包装箱内起作用。
-
带有特性约束的泛型函数使用单态化实现 (monomorphization), 所以它是静态派分的 (statically dispatched)。
- impl Trait
在版本1.26 开始,Rust提供了impl Trait的写法,作为和Scala 对等的既存型别(Existential Type)的写法。 在下面这个写法中,fn foo()将返回一个实作了Trait的trait。
//before fn foo() -> Box<Trait> { // ... } //after fn foo() -> impl Trait { // ... }相较于1.25 版本以前的写法,新的写法会在很多场合中更有利于开发和执行效率。
impl Trait 的普遍用例
trait Trait { fn method(&self); } impl Trait for i32 { // implementation goes here } impl Trait for f32 { // implementation goes here }利用Box 会意味:即便回传的内容是固定的,但也会使用到动态内存分配。利用impl Trait 的写法可以避免便用Box。
//before fn foo() -> Box<Trait> { Box::new(5) as Box<Trait> } //after fn foo() -> impl Trait { 5 }其他受益的用例
闭包:
// before fn foo() -> Box<Fn(i32) -> i32> { Box::new(|x| x + 1) } // after fn foo() -> impl Fn(i32) -> i32 { |x| x + 1 }传参:
// before fn foo<T: Trait>(x: T) { // after fn foo(x: impl Trait) {3.4 泛型(Generics)
当我们实现一个函数或者数据结构时,往往希望参数可以支持不同的类型,泛型可以解决这个问题。 声明参数类型时,换成大写的字母,例如字母 T,同时使用
告诉编译器 T 是泛型。 函数中使用泛型
fn largest<T>(list: &[T]) -> T { let mut largest = list[0]; for &item in list.iter() { if item > largest { largest = item; } } largest } fn main() { let number_list = vec![34, 50, 25, 100, 65]; let result = largest(&number_list); println!("The largest number is {}", result); let char_list = vec!['y', 'm', 'a', 'q']; let result = largest(&char_list); println!("The largest char is {}", result); }结构体使用泛型
struct Point<T> { x: T, y: T, } fn main() { let integer = Point { x: 5, y: 10 }; let float = Point { x: 1.0, y: 4.0 }; }枚举使用泛型
enum Option<T> { Some(T), None, } enum Result<T, E> { Ok(T), Err(E), }Result 枚举有两个泛型类型,T 和 E。Result 有两个成员:Ok,它存放一个类型 T 的值, 而 Err 则存放一个类型 E 的值。这个定义使得 Result 枚举能很方便的表达任何可能成功(返回 T 类型的值) 也可能失败(返回 E 类型的值)的操作。回忆一下示例 9-3 中打开一个文件的场景: 当文件被成功打开 T 被放入了 std::fs::File 类型而当打开文件出现问题时 E 被放入了 std::io::Error 类型。
方法中使用泛型
struct Point<T> { x: T, y: T, } impl<T> Point<T> { fn x(&self) -> &T { &self.x } } fn main() { let p = Point { x: 5, y: 10 }; println!("p.x = {}", p.x()); }3.5 常见集合 Vec
- 新建
let v: Vec<i32> = Vec::new(); // 空集合 // let v = vec![1, 2, 3]; // 含初始值的集合,vec!是为方便初始化Vec提供的宏。 println!("第三个元素 {}", &v[2]); // 3 println!("第100个元素 {}", &v[100]); // panic error assert_eq!(v.get(2), Some(&3)); assert_eq!(v.get(100), None);v.get(2) 和 &v[2] 都能获取到 Vec 的值,区别在于 &v[2] 返回的是该元素的引用, 引用一个不存在的位置,会引发错误。v.get(2) 返回的是枚举类型 Option<&T>。 v.get(2) 返回的是 Some(&3),v.get(100) 返回的是 None。
- 更新
let v: Vec<i32> = Vec::new(); v.push(5); v.push(6); v.push(7); v.push(8); v.pop() //删除最后一个元素- 遍历
let v = vec![100, 32, 57]; for i in &v { println!("{}", i); } let mut v2 = vec![100, 32, 57]; for i in &mut v2 { *i += 50; }- if let 控制流
如果我们想修改Vec中第2个元素的值呢?可以这么写:
fn main() { let mut v = vec![1, 2, 3, 4, 5]; { let third = v.get_mut(2).unwrap(); *third += 50; } println!("v={:?}", v); // v=[1, 2, 53, 4, 5] }因为 v.get_mut() 的返回值是Option
枚举类型,那么可以使用if let来简化代码。 fn main() { let mut v = vec![1, 2, 3, 4, 5]; if let Some(third) = v.get_mut(2) { *third += 50; } println!("v={:?}", v); // v=[1, 2, 53, 4, 5] }- while let 控制流
if let可以用于单个元素的场景,while let就适用于遍历的场景了。
let mut stack = vec![1, 2, 3, 4, 5]; while let Some(top) = stack.pop() { println!("{}", top); // 依次打印 5 4 3 2 1 }对于一个可变数组,Rust提供了一种简单的遍历形式—— for 循环。 我们可以获得一个数组的引用、可变引用、所有权。
let v = vec![1, 2, 3]; for i in &v { .. } // 获得引用 for i in &mut v { .. } // 获得可变引用 for i in v { .. } // 获得所有权,注意此时Vec的属主将会被转移!! // @question 为什么说使用for容易造成嵌套循环但是,这么写很容易出现多层for循环嵌套,因此,Vec提供了一个into_iter()方法,能显式地将自己转换成一个迭代器。
3.6 常见集合 String
Rust 的核心语言中只有一种字符串类型:str,字符串切片,它通常以被借用的形式出现,&str。这里提到的字符串,是字节的集合,外加一些常用方法实现。因为是集合,增持增删改,长度也可变。
- 新建
let mut s1 = String::new(); let s2 = "initial contents".to_string(); let s3 = String::new();- 更新
let mut s = String::from("foo"); s.push_str("bar"); // 附加字符串 s.push('!') // 附加单字符 assert_eq!(s.remove(0), 'f'); // 删除某个位置的字符 let s1 = String::from("Hello, "); let s2 = String::from("world!"); let s3 = s1 + &s2;- format
let s1 = String::from("tic"); let s2 = String::from("tac"); let s3 = String::from("toe"); let s = format!("{}-{}-{}", s1, s2, s3); println!("{}", s); // tic-tac-toe- 索引
let v = String::from("hello"); assert_eq!(Some('h'), v.chars().nth(0));- 遍历
let v = String::from("hello"); for c in v.chars() { println!("{}", c); }在Rust内部,String 是一个 Vec
的封装, 但是有些字符可能会占用超过2个字符,所以String不支持直接索引,如果需要索引需要使用 chars() 转换后再使用。 3.7 常见集合 HashMap
- 新建
use std::collections::HashMap; let mut scores = HashMap::new(); scores.insert(String::from("Blue"), 10); scores.insert(String::from("Yellow"), 50);这里使用了use引入了HashMap结构体。
- 访问
use std::collections::HashMap; let mut scores = HashMap::new(); scores.insert(String::from("Blue"), 10); scores.insert(String::from("Yellow"), 50); let team_name = String::from("Blue"); let score = scores.get(&team_name);- 更新
use std::collections::HashMap; let mut scores = HashMap::new(); scores.insert(String::from("Blue"), 10); // 10 scores.insert(String::from("Blue"), 25); // 25 // Blue 存在则不更新,不存在则更新,因此scores['Blue'] 仍为 25 scores.entry(String::from("Blue")).or_insert(50);4 错误处理
4.1 不可恢复错误 panic!
Rust 有 panic!宏。当执行这个宏时,程序会打印出一个错误信息, 展开并清理栈数据,然后接着退出。出现这种场景,一般是出现了一些不知如何处理的场景。
- 直接调用
fn main() { panic!("crash and burn"); }执行 cargo run 将打印出
$ cargo run Compiling tutu v0.1.0 (/xxx/demo/tutu) Finished dev [unoptimized + debuginfo] target(s) in 0.28s Running `target/debug/tutu` thread 'main' panicked at 'crash and burn', src/main.rs:2:5 note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace.最后2行包含了 panic!导致的报错信息,第1行是源码中 panic! 出现的位置 src/main.rs:2:5
- 代码bug引起的错误
fn main() { let v = vec![1, 2, 3]; v[99]; // 越界 }和之前一样,cargo run 的报错信息只有2行,缺少函数的调用栈,为了便于定位问题, 可以设置 RUST_BACKTRACE 环境变量来获得更多的调用栈信息,Rust 中称之为backtrace。 通过backtrace,可以看到执行到目前位置所有被调用的函数的列表。
例如执行 RUST_BACKTRACE=1 cargo run,这种方式的好处在于,环境变量只作用于当前命令。
$ RUST_BACKTRACE=1 cargo run Finished dev [unoptimized + debuginfo] target(s) in 0.00s Running `target/debug/tutu` thread 'main' panicked at 'index out of bounds: the len is 3 but the index is 99', /rustc/xxx/src/libcore/slice/mod.rs:2717:10 stack backtrace: 0: backtrace::backtrace::libunwind::trace at /cargo/registry/src/github.com-1ecc6299db9ec823/backtrace-0.3.37/src/backtrace/libunwind.rs:88 ... 17: <alloc::vec::Vec<T> as core::ops::index::Index<I>>::index at /rustc/xxx/src/liballoc/vec.rs:1796 18: tutu::main at src/main.rs:4 note: Some details are omitted, run with `RUST_BACKTRACE=full` for a verbose backtrace.第一行的报错信息,说明了错误的原因,长度越界。紧接着打印出了函数调用栈,
src/main.rs:4 -> liballoc/vec.rs:1796 -> …
在windows下,可以执行 set RUST_BACKTRACE=1 && cargo run。
- release
当出现 panic 时,程序默认会开始 展开(unwinding), 这意味着 Rust 会回溯栈并清理它遇到的每一个函数的数据, 不过这个回溯并清理的过程有很多工作。另一种选择是直接 终止(abort), 这会不清理数据就退出程序。那么程序所使用的内存需要由操作系统来清理。
release模式下,希望程序越小越好,可以在Cargo.toml中设置 panic 为 abort。
[profile.release] panic = "abort"4.2 可恢复错误 Result
- 处理 Result
有些错误,希望能够捕获并且做相应的处理,Rust 提供了 Result 机制来处理可恢复错误, 类似于其他语言中的try catch。
这是 Result<T, E>的定义
enum Result<T, E> { Ok(T), Err(E), }有些函数会返回Result,那怎么知道一个函数的返回对象是不是Result呢?很简单!
fn main(){ let f: u32 = File::create("hello.txt"); }当我们编译上面的代码时,将会报错。
= note: expected type `u32` found type `std::result::Result<std::fs::File, std::io::Error>`从报错信息可以看出,File::create 返回的是一个Result<fs::File. io::Error>对象, 如果没有异常,我们可以从Result::Ok
获取到文件句柄。 下面是一个完整的示例,创建 hello.txt 文件,并尝试写入 “Hello, world!”。
use std::fs::File; use std::io::prelude::*; fn main() { let f = File::create("hello.txt"); let mut file = match f { Ok(file) => file, Err(error) => { panic!("Problem create the file: {:?}", error) }, }; match file.write_all(b"Hello, world!") { Ok(()) => {}, Err(error) => { panic!("Failed to write: {:?}", error) } }; }如果执行成功,可以看到在工程根目录下,多出了 hello.txt 文件。
- unwrap 和 expect
Result 的处理有时太过于繁琐,Rust 提供了一种简洁的处理方式 unwrap 。 即,如果成功,直接返回 Result::Ok
中的值,如果失败,则直接调用 !panic,程序结束。 let f = File::open("hello.txt").unwrap(); // 若成功,f则被赋值为文件句柄,失败则结束。expect 是更人性化的处理方式,允许在调用!panic时,返回自定义的提示信息,对调试很有帮助。
let f = File::open("hello.txt").expect("Failed to open hello.txt");- 返回 Result
我们可以实现类似于 File::open 这样的函数,让调用者能够自主绝对如何处理成功/失败的场景。
use std::io; use std::io::Read; use std::fs::File; fn read_username_from_file() -> Result<String, io::Error> { let f = File::open("hello.txt"); let mut f = match f { Ok(file) => file, Err(e) => return Err(e), }; let mut s = String::new(); match f.read_to_string(&mut s) { Ok(_) => Ok(s), Err(e) => Err(e), } }上面的函数如果成功,则返回 hello.txt 的文本字符串,失败,则返回 io::Error。
更简单的实现方式
use std::io; use std::io::Read; use std::fs::File; fn read_username_from_file() -> Result<String, io::Error> { let mut f = File::open("hello.txt")?; let mut s = String::new(); f.read_to_string(&mut s)?; Ok(s) }这种写法使用了?运算符向调用者返回错误。
作用是:如果 Result 的值是 Ok,则该表达式返回 Ok 中的值且程序继续执行。如果值是 Error , 则将 Error 的值作为整个函数的返回值,好像使用了 return 关键字一样。这样写,逻辑更为清晰。
5 包、crate和模块
5.1 包和 crate
. ├── Cargo.lock ├── Cargo.toml ├── benches │ └── large-input.rs ├── examples │ └── simple.rs ├── src │ ├── bin │ │ └── another_executable.rs │ ├── lib.rs │ └── main.rs └── tests └── some-integration-tests.rs一个 Cargo 项目即一个包(Package),一个包至少包含一个crate; 可以包含零个或多个二进制crate(binary crate), 但只能包含一个库crate(library crate)。 src/main.rs 是与包名同名的二进制 crate 的根, 其他的二进制 crate 的根放置在 src/bin 目录下; src/lib.rs 是与包名同名的库 crate 的根。
5.2 模块
模块 让我们可以将一个 crate 中的代码进行分组,以提高可读性与重用性。 即项是可以被外部代码使用的(public),还是作为一个内部实现的内容, 不能被外部代码使用(private)。
- 声明模块
Rust中使用mod来声明模块,模块允许嵌套,可以使用模块名作为路径使用,例如:
// src/main.rs mod math { mod basic { fn plus(x: i32, y: i32) -> i32 { x + y} fn mul(x: i32, y: i32) -> i32 { x * y} } } fn main() { println!("2 + 3 = {}", math::basic::plus(2, 3)); println!("2 * 3 = {}", math::basic::mul(2, 3)); }- 引入作用域
使用use可以将路径引入作用域。
我们在 src/lib.rs 中声明一个模块,在 src/main.rs 中调用。
// src/lib.rs pub mod greeting { pub fn hello(name: &str) { println!("Hello, {}", &name) } // pub 才能外部可见 }// src/main.rs use tutu; fn main() { tutu::greeting::hello("Jack"); // Hello, Jack }路径的长度可以自由定义,也可以写成
// src/main.rs use tutu::greeting; fn main() { greeting::hello("Jack"); }src/main.rs 和 src/lib.rs 属于不同的 crate ,所以引入作用域时,需要带上包名 tutu 。
- 分隔模块
在 src/lib.rs 中可以使用 mod 声明多个模块,但有时为了可读性,习惯将每个模块写在独立的文件中。
新建 src/greeting.rs,写入
// src/greeting.rs pub fn hello(name: &str) { println!("Hello, {}", &name) }在 src/lib.rs 可以这样使用,
// src/lib.rs pub mod greeting; pub fn func() { greeting::hello("Tom"); }关键点就在于mod greeting;这一行,mod greeting后面没有具体实现,而是紧跟分号,则声明 greeting 的模块内容位于 src/greeting.rs 中。
其他crate,例如 src/main.rs 中的使用方式没有任何变化。
// src/main.rs use tutu::greeting; fn main() { greeting::hello("Jack"); }6 测试
6.1 单元测试(unit tests)
fn plus(x: i32, y: i32) -> i32 { x + y } fn main() { let x = 10; let y = 20; println!("{} + {} = {}", x, y, plus(x, y)) } #[test] fn it_works() { assert_eq!(4, plus(2, 2), ); }单元测试非常简单,只需要在每一个测试用例前加上 #[test] 即可,通过 cargo test 执行用例。
$ cargo test running 1 test test it_works ... ok test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out更规范的写法是在每个源文件中,创建包含测试函数的 tests 模块,测试用例写在 tests 模块中,并使用 cfg(test) 标注模块。
fn plus(x: i32, y: i32) -> i32 { x + y } fn main() { println!("2 + 3 = {}", plus(2, 3)); } #[cfg(test)] mod tests { use super::*; #[test] fn it_works() { assert_eq!(4, plus(2, 2), ); } }因为内部测试的代码和源码在同一文件, 因而需要使用 #[cfg(test)] 注解告诉 Rust 只在执行 cargo test 时才编译和运行测试代码, 因此,可以在构建库时节省时间,并减少编译文件产生的文件大小。
单元测试的好处在于,可以测试私有函数。如果在独立的目录,例如 tests 下做测试, 则只允许测试公开接口,即使用 pub 修饰后的模块和函数。
6.2 集成测试(integration tests)
集成测试用例和源码位于不同的目录,因而源码中的模块和函数, 对于集成测试来说完全是外部的,因此,只能调用一部分库暴露的公共API。 Cargo 约定集成测试的代码位于项目根路径下的 tests 目录中, Cargo 会将 tests 中的每一个文件当做一个 crate 来编译。
只有库 crate 才会向其他 crate 暴露可供调用的函数, 因此在 src/main.rs 中定义的函数不能够通过 extern crate 的方式导入,所以也不能够被集成测试。
src/main.rs 定义了 main 函数,即作为一个可执行(Executable)程序入口, 目的是独立运行,而非向其他 crate 提供可供调用的接口。
我们将 plus 函数移动到 src/lib.rs 中,新建 tests/test_lib.rs,最终的目录结构如下
├── Cargo.toml ├── src │ └── lib.rs │ └── main.rs ├── tests └── test_lib.rs// src/lib.rs pub fn plus(x: i32, y: i32) -> i32 { // plus 必须是公共API,才能被集成测试。 x + y }// src/main.rs use tutu; fn main() { println!("2 + 3 = {}", tutu::plus(2, 3)); }// tests/test_lib.rs use tutu; #[test] fn it_works() { assert_eq!(4, tutu::plus(2, 2)); }运行 cargo test,将输出
running 1 test test it_adds_two ... ok test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out7 生命周期
- 借用不改变内存的所有者(Owner),借用只是对源内存的临时引用。
- 在借用周期内,借用方可以读写这块内存,所有者被禁止读写内存;且所有者保证在有“借用”存在的情况下,不会释放或转移内存。
- 失去所有权的变量不可以被借用(访问)。
- 在租借期内,内存所有者保证不会释放/转移/可变租借这块内存,但如果是在非可变租借的情况下,所有者是允许继续非可变租借出去的。
- 借用周期满后,所有者收回读写权限
- 借用周期小于被借用者(所有者)的生命周期。
-
从 Vim 切换至 SpaceVim 的细节
准备工作
在切换至 SpaceVim 之前,需要先简单了解下以下几点:
- 什么是 SpaceVim?
SpaceVim 是一套社区驱动的模块化 Vim 配置文件,因此还是需要安装 Vim 或者 Neovim。 建议使用 Neovim,因为 Neovim 的一些功能(
+py、+py3)扩展以及内置的 API 更加容易使用。- 如何安装 SpaceVim?
迁移成本
相信这个是大多数 Vim 老用户顾虑和担心的事情,担心需要改变按键习惯,担心改变配置习惯。
- 按键习惯
SpaceVim 内置的快捷键都是以
SPC为前缀键,不占用Leader键,这就意味着原先的一些 以Leader为前缀的快捷键,可以无缝迁移过来。- 配置习惯
同样是可以支持书写 Vim Script,只不过书写的位置不一样。原先可以在
~/.vimrc这个文件内 书写 Vim Script,在 SpaceVim 内引入了一个新的概念,启动函数,这是一个当 SpaceVim 启动 时候会被调用的函数,可以将 Vim 脚本写在这个函数内,比如:function! myspacevim#init() let g:focus_was_lost = 0 set notitle endfunction
-
SpaceVim 下的异步任务系统
项目的构建、打包、测试通需要调用一些外部命令,比如
make、ant等,SpaceVim 内置一个任务管理系统,通过分析项目的任务配置文件,获取相关命令,并且异步执行,同时根据配置按照需求展示运行结果。配置文件
配置文件支持全局配置文件以及项目局部配置文件,分别为
~/.SpaceVim.d/tasks.toml和.SpaceVim.d/tasks.toml,局部配置文件具有更高的优先权限。基本使用
以下为一个简单的 hello world 示例:
[my-first-task] command = 'echo' args = ['hello world']添加以上内容至
~/.SpaceVim.d/tasks.toml后,在SpaceVim内按下SPC p t r快捷键,就会弹出如下界面:可以使用
j/k按键进行上下选择,回车键执行,也可以按下任务名称前面的序号直接执行。执行效果如下:进阶使用
对于一些复杂的任务,可以使用预定义的一些变量,来简化配置文件,比如,在一个简单的C项目里:
[in]: e:/ctest/ ▶ bin/ ▼ src/ main.c编译一个简单的编译当前C文件
src/main.c至bin/目录,以及调用编译后的可以执行文件运行:[file-build] command = 'gcc $(file) -o $(workspaceFolder)/bin/$(workspaceFolderBasename)' [file-run] command = "$(workspaceFolder)/bin/$(workspaceFolderBasename)"上面的配置文件里涉及到的变量分别是:
变量名 值 $(file)e:/ctest/src/main.c$(workspaceFolder)e:/ctest$(workspaceFolderBasename)ctest
SpaceVim 中文官网: https://spacevim.org/cn/
中文 Gitter 聊天室:https://gitter.im/SpaceVim/cn
-
心型脂肪酸结合蛋白(H-FABP)检测的临床意义
冠心病急性心肌梗死(AMI)是世界范围内严重威胁人类生命的疾病, 早期诊断急性心肌梗死对挽救病人生命非常重要。近年来, 人们提出心肌型脂肪酸结合蛋白(H-FABP)可以作为早期诊断急性心肌梗死的心肌标志物。 H-FABP 是一种低分子量胞浆蛋白,在心肌细胞中含量丰富,由于分子量较小, 在急性心肌梗死后 1.3 ~ 3 小时内血浆浓度开始升高。国外一些临床研究已经证实, H-FABP 早期诊断急性心肌梗死较肌红蛋白有更好的特异性和敏感性,尤其在 AMI 早期 3 小时内有更好的诊断价值。
什么是 H-FABP?
脂肪酸结合蛋白(FABPs)是一种小的胞质蛋白,在心脏和肝脏等具有活跃脂肪酸代谢的组织中大量表达(Viswanathan 等人 2012), 其主要功能是促进细胞内长链脂肪酸转运。9 种不同类型的 FABPs 家族已被确定,其中心脏型 FABP(H-FABP)是最为广泛研究的, 主要是由于在心肌细胞中发现的丰富。
它们的低分子量和细胞质位置的结合意味着 h-fabp 蛋白在急性心肌梗死(AMI)后最早被释放进入血液:
生物标志物 分子量 (kDa) 初始检测时间 到达峰值 回到正常值 备注 H-FABP 15kDa 30 分钟 6-12 小时 24 小时 Early rise specificity Myoglobin 17kDa 1-3 小时 5-8 小时 16-24 小时 Early rise Low specificity Troponin I (TnI) 22kDa 3-6 小时 14-18 小时 5-10 天 Late rise High specificity Troponin T (TnT) 33kDa 3-6 小时 10-48 小时 10-15 天 Late rise High specificity CK-MB 86kDa 3-8 小时 9-24 小时 48-72 小时 Late rise High specificity 与传统心肌标志物比较
与传统的心肌标志物相比较,心型脂肪酸结合蛋白在早期诊断急性心肌梗死具有更好的特异性和敏感性。
H-FABP 测定的临床应用
早期诊断急性心肌梗死:H-FABP 血浆释放特点与肌红蛋白相同,但 HFABP 在心肌细胞内的含量高于 Mb,而在血浆内的含量远低于 Mb。因此,当心肌损伤后,血浆 HFABP 迅速升高超正常上限,比 Mb 和肌钙蛋白来得快,因而更有诊断价值。近年来众多研究表明血清 H-FABP 能识别超急期急性心肌梗死,特别是胸痛发病 6 h 内的患者,对决定是否住院、冠状动脉造影、介入治疗有很大帮助。
评估心肌梗死面积:Wodzig 等测定 20 例 AMI 患者的 H-FABP、Mb、肌酸激酶同工酶(CK-MB)、羟丁酸脱氢酶(HBDH),用 H-FABP 或 Mb 曲线,与用 CK-MB 或 HBDH 评估梗死面积具有较好的一致性。H-FABP 或 Mb 可用评估肾功能正常 AMI 患者发病 24 h 内的梗死面积。
评估再灌注损伤:58 例 AMI 患者行溶栓治疗,溶栓后 90min 行冠状动脉造影,溶栓前、溶栓后 60、90 min 和 180 min 分别测定 H-FABP 和 Mb 浓度。溶栓后相关血管开通者 H-FABP 和 Mb 明显高于未开通者。研究者认为: H-FABP、Mb 可作为再灌注指标,结合梗死面积分析,灵敏度和特异性可进一步提高。
评估心力衰竭严重程度与预后:Setsuta 等测定 103 例慢性心衰患者 H-FABP 及 cTnI,发现 cTnI≥0. 01μg /L 而且 H-FABP≥4.5μg/L 者心血管事件(死亡、病情加重再入院)发生率高于其它患者,提示 H-FABP 联合 cTnI 能独立预测心血管事件。
预测急性冠状动脉综合征心血管事件:在 ACS 发病早期的几小时内,筛选出可能发生心脏事件的高危患者很重要。最近已有报导血浆 H-FABP 浓度升高与心血管事件发生率及心血管死亡有关。Viswanathan 等入选 955 例怀疑 ACS 而肌钙蛋白阴性的患者(除外 ST 抬高性心肌梗死及新发左束支传导阻滞患者) ,于症状发生后 12 ~ 24h 检测 H-FABP,平均随访 18 个月后,H-FABP 浓度> 6.48 mg/L 者不良事件显著增加,提示 H-FABP 能独立预测中低危胸痛患者的心血管事件。
区分心肌或骨骼肌损伤:H-FABP 主要来自心肌,少部分来自骨骼肌。心脏电除颤、器官衰竭、手术后、强体力活动如跑步、划船,骨骼肌受损伤,也会引起血中 H-FABP 浓度升高。Mb/H-FABP 比值可用于鉴别心肌损伤(比值=2 ~ 10)和骨骼肌损伤(比值=20 ~ 70)。AMI 患者,血浆 Mb/H-FABP 比值为 0 ~ 5。
急性冠脉综合征的预后价值
除了对急性冠脉综合征有重要的诊断价值外,H-FABP 在这些患者的长期预后中也显示出巨大的价值, 即使与高灵敏度肌钙蛋白测定相比也是如此。
Kilcullen(JACC 2007)在 2007 年美国心脏病学会杂志上发表了一项前瞻性观察研究的详细资料, 详细介绍了在英国 11 家医院中 1448 名确诊急性冠脉综合征患者的队列。 患者在 ACS 症状出现 12-24 小时后,从单个血液样本中测量肌钙蛋白 I 和 H-Fabp。 随访 1 年后,发现 H-Fabp 浓度的升高对急性冠脉综合征后的死亡率具有很强的预测作用, H-Fabp 能够在整个 TNI 浓度范围内识别高危患者。 6 个月时 h-fabp 和肌钙蛋白 I 均为阴性的患者死亡率为 0%, 因此被认为是非常低的风险。 然而,与 H-Fabp 阴性的患者相比,H-Fabp 阳性和肌钙蛋白阴性的患者在 1 年后死亡的风险明显较高。

Fig 5: Kaplan-Meier mortality curves for patients with either TnI≤0.06 μg/l (unstable angina) or TnI>0.06 μg/l (MI inclusive of STEMI/BBBMI) according to the H-FABP cut-off value of 5.8μg/l.
这些患者接受了 6 年的随访,除了肌钙蛋白阴性、H-Fabp 阳性的患者组在 6 年后死亡率最高(Pearson 等人,20109)。H-Fabp 不仅是一个独立的预后标志物,而且可以识别被认为是肌钙蛋白阴性的高危患者。
H-FABP 与其他项目联合检查
下图为不同心肌标志物组合检查对于 AMI 症状出现时间的敏感性,由图中可以看出心型脂肪酸结合蛋白和肌钙蛋白 I 联合检查具有更高的敏感性。
H-FABP、cTnI 联合诊断 ACS
有研究表明应用心型脂肪酸结合蛋白(H-FABP)与肌钙蛋白 Ⅰ(cTnI)联合诊断 ACS 研究发现,相比单纯的检测而言,能够提高检测的阳性率,同时对于检测准确性和诊断敏感性的提高具有重要价值,因此更加值得临床借鉴,意义在于通过联合检测提高诊断率,便于临床及时对患者进行准确的治疗,从而提高治疗效果,改善患者预后情况。
H-FABP、肌钙蛋白 I、超敏 C 反应泛白联合诊断 AMI
hs-CRP、H-FABP、cTnT 联合检测诊断 AMI 的特异度、阳性预测值均达到了 100.0%,同时敏感度、阴性预测值也较高,达到了 97.8%。这说明心型脂肪酸结合蛋白、肌钙蛋白 T、超敏 C 反应蛋白联合检测,对于诊断急性心肌梗死具有较高的阳性预测值和特异度,其能有效降低误诊率,值得推广应用。
参考文献:
- 《心型脂肪酸结合蛋白(H—FABP)与肌钙蛋白 I(cTnI)联合诊断 ACS 的价值》- 中西医结合心血管病电子杂志 2017 年 4 期
- 《Clinical Value of H-FABP》
- 《心型脂肪酸结合蛋白、肌钙蛋白 T、超敏 C 反应蛋白联合检测在急性心肌梗死中的价值》- 中国医药科学杂志 2014 年 10 月第 4 卷第 19 期
-
右键使用 SpaceVim 打开文件
我们知道,在 Linux 命令行里,可以使用 cd 命令切换到项目所在的目录, 此时启动 SpaceVim,会读取工程目录下的一些 SpaceVim 配置信息。 这样的好处有很多,假定我日常需要编辑 Java Python 和 c 语言项目, 那么在使用SpaceVim时不需要在用户配置里将所有的语言模块都启用了, 而是只需要在 Java 项目根目录创建一个
.SpaceVim.d/init.toml文件, 在此文件里启用lang#java模块即可。同理,在 Python 项目根目录同样操作启用lang#python模块即可。但是在 windows 系统下使用 neovim-qt 时,就不太方便了,为此,添加了这一功能,可以使用 windows 自身的文件管理器,定位到项目所在位置后使用右键打开 SpaceVim 并读取项目下的 SpaceVim 配置。
下面,我们来看看如何添加:
- 按下
Win + r在运行弹窗理输入:regedit回车,打开注册表编辑器:

- 定位到 HKEY_CLASSES_ROOT > * > shell :

右键新建项,此时可以输入一个你需要看到的名字,比如 使用 SpaceVim 打开, 再在这个项里新建一个 command 项,修改其默认值为:
"D:\Program Files\Neovim\bin\nvim-qt.exe" -qwindowgeometry 1310x650+20+20 "%1"最新版 Neovim 修改为:
nvim --server \\.\pipe\nvim-pipe-123123123 --remote "%1"需要在 Neovim 的配置文件里面增加:
pcall(function() vim.fn.serverstart([[\\.\pipe\nvim-pipe-123123123]]) end)此时,就可以在右键中使用 neovim-qt 打开文件了,上面启动参数里指定了窗口位置和大小,可以自行调节。

- 按下
-
使用 Vim 管理待办事项
简介
这一功能主要是方便检索源码中的待办事项。只需要在源码注释中加入相关标签即可,比如
" @todo Use new prolog plugin " call add(plugins, ['wsdjeg/prolog-vim', { 'merged' : 0}]) call add(plugins, ['wsdjeg/prolog.vim', { 'merged' : 0}])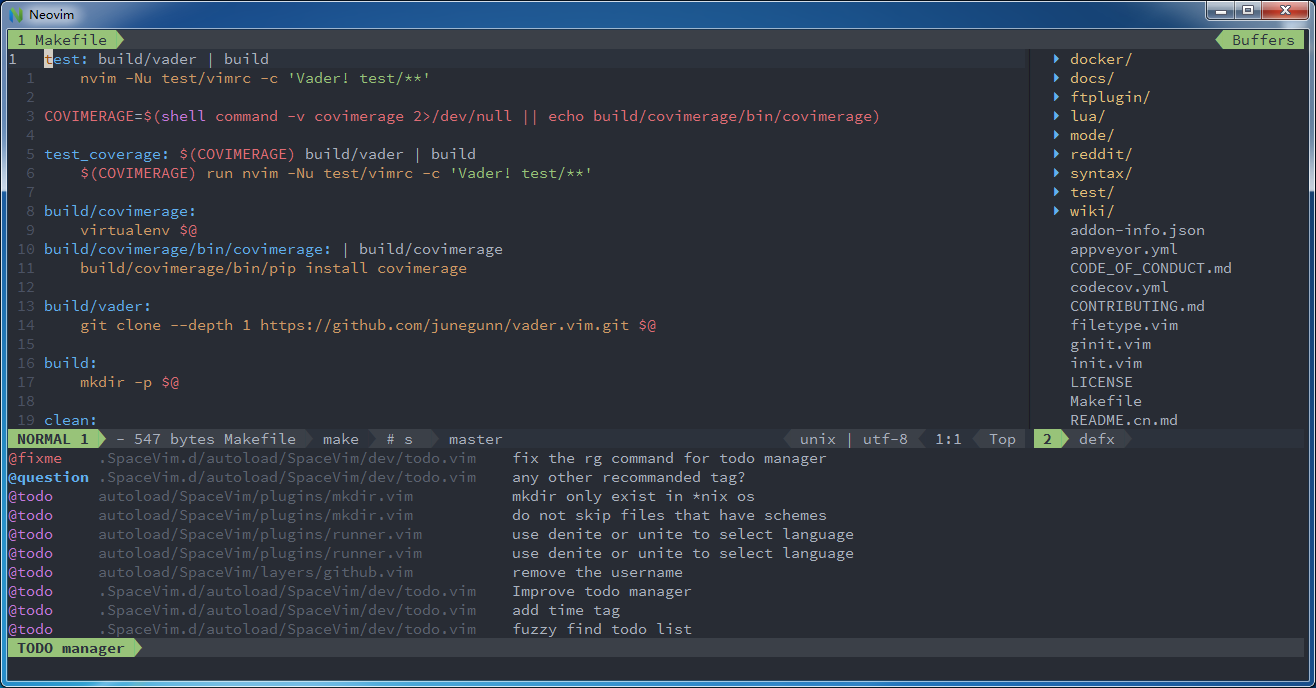
安装
vim-todo 这一插件分离自 SpaceVim,可以在 SpaceVim 中使用,当然也支持独立安装。 可以使用任意插件管理器,比如 dein 来安装 vim-todo:
call dein#add('wsdjeg/vim-todo')这一插件依赖于 Vim 的
+job特性,因此需要确保你的 Vim 版本满足要求,并且需要安装一个命令行工具 rg